
Written by:
Editorial Team
Editorial Team
Learning how to clean data is a systematic process for finding and fixing errors, inconsistencies, and inaccuracies in datasets. The process involves removing duplicate records, correcting structural errors, and handling missing values to ensure the information is reliable. This is the foundational step for any dependable AI or business intelligence system.
Why Clean Data Is Your AI's Foundation

The phrase "garbage in, garbage out" describes a high-stakes reality for any enterprise. Inaccurate or inconsistent data directly impacts the business, sabotaging everything from quarterly BI reports to multi-million dollar AI initiatives.
For leaders deploying AI, data cleaning is a strategic imperative. A disciplined, systematic approach to data quality has a direct impact on ROI, helps avoid operational risks, and builds a competitive advantage.
The Business Case for Prioritizing Data Quality
Poor data quality can halt business operations. Flawed datasets lead to misguided forecasts, wasted resources, and a lack of trust in the numbers. Momentum slows when teams spend more time questioning data than acting on insights.
The financial impact is significant. A 2023 survey by an industry analytics firm found that more than 25 percent of data and analytics professionals believe their organizations lose over $5 billion annually due to poor data quality. These figures show a widespread and expensive problem that requires a new approach to data management.
This is why data cleaning must be a core, non-negotiable step in the AI lifecycle.
From Tactical Fixes to Strategic Advantage
Shifting data quality from a reactive fix to a continuous, proactive discipline is transformative. Building reliable enterprise AI depends on robust financial data quality management. When data is consistently clean, it becomes an asset that fuels innovation.
A proactive data quality strategy ensures AI models are trained on accurate information from the start. This reduces the risk of biased or incorrect outputs that can damage brand reputation and break customer trust.
A commitment to clean data delivers three primary benefits:
- Improved Model Performance: AI models built on clean data perform better. Their predictions are more accurate and their insights are more reliable, which directly translates to business value.
- Increased Team Efficiency: Data scientists and engineers can reduce the time spent cleaning messy data, which can account for up to 80% of their workload according to various industry reports. Instead, they can focus on building innovative solutions.
- Enhanced Decision-Making: Leaders can make strategic decisions with confidence, knowing the supporting data is accurate, complete, and consistent across the organization.
For organizations seeking to assess their current data health, a structured audit is a good starting point. You can begin to identify your most critical quality gaps by exploring a comprehensive data and AI audit here: https://dsg.ai/audit
Diagnosing Your Data Quality Problems
You cannot fix what you do not measure. Before writing any code, the first step in data cleaning is a clear, diagnostic assessment of your data's health.
Jumping into corrections without a proper assessment is a common mistake. It is like performing surgery without an X-ray; you might address a symptom while missing the underlying cause. This initial phase, known as data profiling, provides a framework for uncovering hidden issues that can corrupt models and analytics. It moves you from a general sense that "the data is messy" to a specific, quantifiable understanding of the problems.
Creating Your Data Quality Report Card
Think of this as creating a "data quality report card" for key datasets. This report provides a baseline to measure against, helping you prove the value of your cleaning efforts later. A solid diagnostic process is foundational to cleaning data in a structured, repeatable way.
A good starting point is to look at core metrics:
- Completeness: What percentage of your data is present? Calculating the completion rate for critical columns (e.g.,
customer_emailortransaction_amount) highlights missing value problems. In our experience, a completion rate below 95% in a key field often points to a systemic issue in data collection. - Validity: Does the data follow expected rules? This concerns format and conformity. Check if a 'date' column contains valid dates, if a 'phone_number' column follows a standard pattern, or if a categorical field like 'product_status' only contains allowed values ('active', 'discontinued', 'backordered').
- Uniqueness: How many duplicates are in your dataset? This is crucial for records that should be unique, like customers or products. A high duplication rate can distort analytics and create operational issues, such as sending multiple marketing emails to the same customer.
Digging Deeper with Statistical Analysis
After covering the basics, apply statistical methods to find less obvious problems. These techniques help you understand the distribution and integrity of your data.
Frequency distributions, for example, are effective for spotting illogical entries. If you run one on a customer_age column that should be numeric, you might find text entries like 'N/A' or 'Refused' that were incorrectly coded. These anomalies would cause errors in later calculations, but a frequency analysis identifies them immediately.
Outlier detection is another powerful tool. By calculating summary statistics like mean, median, and standard deviation, you can flag values that fall far outside the expected range.
Here is a synthetic example: In a B2B transaction dataset, the average order is $5,200 with a standard deviation of $1,500. An order appears for $5,200,000. This is a classic outlier. It is almost certainly a data entry error, and if left unchecked, it would drastically skew any predictive model.
Ensuring Structural and Relational Integrity
Finally, you must examine the entire data ecosystem. The diagnostic process should not stop at individual tables; real problems often appear when you join data from multiple sources.
Schema validation ensures database tables adhere to their defined structure. Are the data types correct? It is common for a field intended for integers to contain text. These misaligned data types are a frequent cause of ETL pipeline failures.
Cross-table consistency checks are equally important. This is where you verify referential integrity. For instance, does every order_id in your payments table correspond to a real entry in the orders table? If not, you have orphaned records and broken relationships that undermine the reliability of your analysis. These structural checks ensure your data is not just clean, but logically sound.
Getting Your Hands Dirty: Practical Data Cleaning Techniques
Once you have diagnosed your data's problems, it is time for the hands-on work of cleaning. Applying the right technique to the right problem distinguishes a fragile AI model from one that is robust and reliable.
These methods are core components of a production-ready data pipeline. The goal is to systematically improve data quality at scale, turning messy, inconsistent information into a valuable asset.
Tackling Duplicates with More Than Just a Simple Delete
Duplicate records are a common data quality issue. In a business context, they distort analytics, inflate marketing costs, and lead to poor customer experiences. In an enterprise environment, looking for exact matches is insufficient.
This is where fuzzy matching is necessary. Instead of looking for perfect matches, these algorithms calculate a similarity score between records to find "almost-the-same" entries common in real-world databases.
- Synthetic Scenario: Imagine your CRM has "Johnathan Smith, 123 Main St." and "Jon Smith, 123 Main Street." A basic deduplication script will miss this.
- The Fix: A fuzzy matching algorithm, like one based on Levenshtein distance, can identify the high similarity in both names and addresses. It flags them as probable duplicates for review or automatic merging. Based on our project experience, implementing this can reduce customer data duplication by an additional 15-25% compared to exact matching alone.
Standardizing the Chaos of Inconsistent Formats
Inconsistency is a common challenge in data projects. When data comes from different systems, is entered by different people, or is pulled from various APIs, it rarely follows a single, clean format. Aggregating or analyzing such data is difficult.
This is where standardization, or normalization, is applied. It is the process of converting data into a consistent, predictable format. It is essential for categorical data, addresses, and units of measure.
Consider a logistics company tracking shipment weights. One system might log weight in pounds (lbs), while another uses kilograms (kg). If this mixed data is fed into a model to forecast shipping costs, the results will be incorrect.
The solution is to establish a single, canonical format and apply a transformation rule. For example, all weights must be in kilograms. Every entry is converted before it reaches the model. This ensures every data point is comparable—a non-negotiable for machine learning.
The same logic applies to phone numbers, addresses, and dates. Agree on a single structure (YYYY-MM-DD for dates, for example), enforce it, and you will eliminate a major source of ambiguity and error.
Intelligently Handling the Gaps: Missing Values
Missing data is a common occurrence. The immediate reaction might be to delete any row with a blank cell, but this can result in losing valuable information from other columns. The key is to handle these gaps intelligently.
Here are a few common and effective approaches:
- Mean/Median/Mode Imputation: A quick method. You replace missing numerical values with the average (mean) or middle value (median) of that column. For categorical data, you use the most frequent value (mode). This is fast but can reduce the natural variance in your data. It is best used when a column is missing a small fraction of its values, typically under 5%.
- Model-Based Imputation: For more important features, a more sophisticated approach is possible. A machine learning model (like k-nearest neighbors or a simple regression) can be trained to predict the missing value based on other available data in that row. This requires more work but often produces more realistic results, especially when dataset variables are strongly related.
- Creating an "Unknown" Category: Sometimes, the fact that a value is missing is informative. In a customer survey, a person who does not answer a question about their income might behave differently from those who do. In these cases, you can treat "missing" as its own category, like 'Unknown' or 'Not Provided'.
The choice of imputation method depends on the data and the model's objective. Always document the method used and, if possible, test how different imputation strategies affect model performance.
Managing Outliers Without Tossing Out Good Information
Outliers—data points that are far from others—can be tricky. As seen during discovery, they could be data entry errors or genuine, rare events. Deleting them immediately is risky; you might discard the most interesting part of your dataset.
Instead of removal, consider these strategies:
- Capping (Winsorization): This technique manages extreme values without deleting them. You set a ceiling and a floor, typically a high and low percentile. For example, any value above the 99th percentile is replaced with the 99th percentile value. This keeps the record but reduces its power to skew analysis.
- Transformation: Applying a mathematical function, like a logarithm, can pull in the long tail of a skewed distribution. This reduces the influence of extreme outliers by bringing them closer to the rest of the data.
- Binning: For numerical outliers, another option is to group them into a special category. For instance, any purchase over a certain amount could be put into a bin labeled "High-Value Transaction." This lets the model treat these events as a distinct group without their raw values distorting the entire scale.
This quick reference table maps common data problems to their solutions.
Common Data Errors and Their Cleaning Solutions
This table helps identify data quality issues and select effective techniques to fix them.
| Data Quality Issue | Description | Primary Cleaning Technique | Example Scenario |
|---|---|---|---|
| Duplicate Records | The same entity exists multiple times, often with minor variations. | Fuzzy Matching & Merging | A customer "Jane Doe" and "J. Doe" at the same address appear as two separate contacts in a CRM. |
| Inconsistent Formats | Data representing the same concept is stored in different formats. | Standardization / Normalization | Product weights are recorded in both "lbs" and "kg" in the same column. |
| Missing Values | Data fields are empty or contain null entries. | Imputation (Mean, Model-based, etc.) | A customer's age is missing in a dataset used for demographic segmentation. |
| Outliers/Anomalies | Data points that deviate significantly from other observations. | Capping, Transformation, or Binning | A single product order has a quantity of 99,999 due to a typo, while most orders are under 100. |
| Structural Errors | Data doesn't conform to the expected schema or data type. | Type-Casting & Validation | A column for "Order Date" contains text strings like "N/A" instead of valid YYYY-MM-DD formats. |
| Incorrect Categorical Data | Misspellings or variations in categorical labels. | Mapping & Consolidation | A "Country" column contains "USA", "U.S.A.", and "United States" as separate categories. |
By mastering these core techniques, you can move from ad-hoc fixes to building a systematic, repeatable process for data cleaning. This builds a foundation of accuracy and reliability for your AI and analytics initiatives.
Scaling Your Efforts with Tools and Automation
Manual data cleaning does not scale. When dealing with millions or billions of records, a hands-on approach is inefficient. To manage data quality effectively, you must build automated, repeatable cleaning pipelines.
The goal is to shift from being reactive to proactive. A resilient system cleans data systematically as it flows in. This frees data scientists and engineers from repetitive data preparation so they can focus on building models and driving strategy.
The Modern Data Cleaning Stack
Options for automating data cleaning range from open-source libraries to enterprise platforms. The right choice depends on your team's skillset, current tech stack, and data volume.
Many teams start with open-source tools.
- Pandas (Python): This is a go-to tool for many data scientists. It is effective for finding duplicates, handling nulls, standardizing formats, and performing complex transformations in a Python environment. It is well-suited for in-memory processing on moderately sized datasets.
- Dask/Vaex (Python): When data no longer fits into memory, libraries like Dask or Vaex are useful. They extend Pandas-like functionality to large datasets by parallelizing work across multiple cores or a cluster.
For larger, integrated environments, dedicated platforms can offer more structure and governance. Enterprise-grade tools often provide advanced capabilities like AI-powered cleaning suggestions, data lineage tracking, and user interfaces that allow non-coders to define cleaning rules.
The secret is to pick tools that fit into your team's existing workflow. The best tool is one that people will use regularly, turning data cleaning from a special project into an automated part of the process.
Embedding Quality Checks into Data Pipelines
The most effective way to maintain high-quality data is to build checks directly into ingestion and transformation pipelines. Validate data as it enters your system, not after it has landed in your warehouse and potentially affected downstream models and reports.
This means embedding automated quality checks into your ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes. Building a robust data pipeline is the foundational skill needed to automate these efforts at scale.
By weaving checks into your pipelines, you can programmatically enforce rules:
- Schema Enforcement: Instantly reject data that does not match the expected structure, such as wrong data types or incorrect column names.
- Validity Constraints: Ensure values fall within an expected range or belong to an approved list of categories.
- Completeness Thresholds: Trigger an alert or halt the pipeline if the percentage of missing values in a key field exceeds a set limit, for example, 5%.
These automated gates are your first line of defense. They stop bad data at the source, preventing it from contaminating your analytics and AI systems.
The Rise of Data Observability
Pipeline checks are effective for known problems. For unpredictable issues, data observability is key.
Modern observability platforms provide continuous, automated monitoring across data systems. They learn the normal patterns of your data—its volume, freshness, and distribution—and alert you to deviations. This helps you catch subtle data drift, unexpected schema changes, or pipeline failures that could silently degrade the accuracy of your AI models.
You can learn more about achieving this level of control with modern data and AI orchestration.
The growth in this area is notable. The global market for data cleaning tools, valued at USD 4.5 billion in 2025, is projected to reach USD 18.6 billion by 2034, expanding at a compound annual growth rate of 17.1%, according to Research and Markets. This growth highlights that high-quality data is the foundation of successful AI.
Weaving Data Cleaning into Your MLOps Lifecycle
Data cleaning should be a daily operational discipline, not a one-time project. It must be integrated into your machine learning lifecycle. Successful AI teams move beyond ad-hoc fixes and build an operationalized data quality framework. Teams that do not are stuck in a cycle of troubleshooting and model retraining.
This means integrating cleaning processes into your MLOps and data governance strategy. You must establish clear ownership, define what "good" data looks like for your use case, and automate the enforcement of those standards. Without this, even sophisticated models will eventually fail as new, messy data enters your pipelines.
The goal is to embed automated quality checks directly into your data pipelines, creating a system that flags issues before they reach a model.
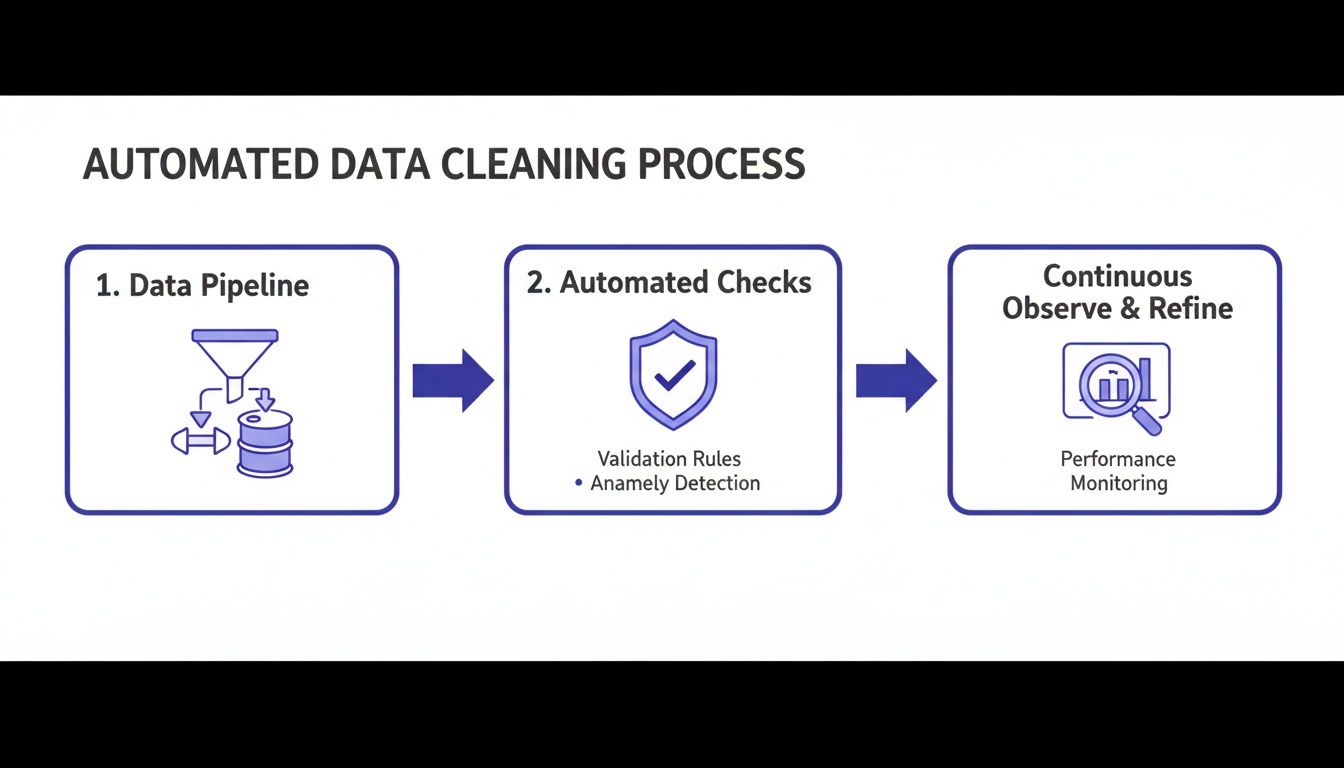
The key takeaway is that data quality is not a separate step. It is a series of automated checks and balances that occur continuously as data flows through your infrastructure.
Establish Clear Ownership and Quality Metrics
Before writing automation code, you must answer: who owns the quality of this dataset? This concept, data ownership, is the cornerstone of any effective governance plan. A designated data owner or steward is responsible for defining, maintaining, and answering for the quality standards of their specific data domain.
With ownership established, you can define meaningful quality metrics. These must be tied to business outcomes.
- Accuracy: How well does the data reflect reality? For a customer address database, a good metric might be the percentage of records successfully validated against a postal service API, with a target of 98% or higher.
- Completeness: Are critical fields filled out? For an e-commerce transaction dataset, fields like
product_idandpurchase_priceshould have 100% completeness. - Timeliness: Is the data fresh enough to be useful? A logistics company might need shipment status data that is no more than five minutes old.
- Consistency: Does the data tell the same story across different systems? If your sales CRM and finance platform show different revenue figures for the same quarter, there is a consistency problem.
These metrics form a service-level agreement (SLA) for your data. They create a clear contract, setting expectations for data producers and giving data consumers, like your ML models, a reliable standard.
Integrate Data Validation into CI/CD for Machine Learning
The most effective place to enforce data standards is within your CI/CD (Continuous Integration/Continuous Deployment) pipelines. Just as you run unit tests on application code before deployment, you should run validation tests on data before using it to train a model.
Tools like Great Expectations or the testing features in dbt are valuable here. They let you codify quality metrics as "expectations" or tests that your data must pass.
For instance, you could configure a data validation gate in your pipeline that automatically verifies:
- The
customer_agecolumn is always between 18 and 99. - The
country_codecolumn only contains valid ISO 3166-1 alpha-2 codes. - The
transaction_idfield has zero null values.
If an incoming batch of data fails these checks, the pipeline can be configured to halt. This gate prevents bad data from being used to retrain a flawed model, avoiding potential production issues. For more on how this fits into a broader operational strategy, a platform like manageAI Monitoring can show you how to tie these checks to overall model performance.
The Critical Role of Documentation and Compliance
Finally, every cleaning rule, transformation, and validation check must be documented. This is not just for internal clarity. In regulated industries like finance or healthcare, it is a requirement for audits and compliance.
Your documentation should be clear, version-controlled, and accessible. Anyone should be able to look at a dataset and understand its journey from raw source to cleaned asset. This transparency builds trust in your data and ensures you can always trace a model's prediction back to its source. It is proof that you know how to clean data in a repeatable, defensible, and enterprise-ready way.
Measuring the Business Impact of Clean Data
Data cleaning is a business imperative that must deliver a return on investment. To get executive buy-in and secure resources, you must connect your team's efforts to concrete business outcomes.
This changes the narrative. Instead of being a cost center, data quality becomes an engine for growth, efficiency, and innovation. The key is to stop talking in terms of "null values removed" and start speaking in terms of efficiency gains, cost savings, and new revenue.
Key Performance Indicators for Data Quality
To make your case, you need numbers. Establish a baseline and track a focused set of Key Performance Indicators (KPIs) that tie your data cleaning work to business performance.
We have seen clients succeed by focusing on a few key areas:
- Operational Efficiency: How much less time are people spending manually fixing data errors? A solid data quality initiative can result in a 15-20% decrease in operational mistakes in areas like logistics or billing.
- Team Productivity: Consider the hours your data scientists and analysts get back. We helped a client automate their cleaning pipelines, and their data science team saw a 30% jump in efficiency because they spent less time on data prep.
- AI Model Performance: Cleaner data means better models. You should track a 5-10% improvement in prediction accuracy or a reduction in model drift. This directly shows that high-quality data produces more reliable AI.
- Customer Data Accuracy: Look at the percentage of complete and accurate customer records. Improving this metric directly impacts the bottom line by reducing costs from returned mail or bouncing marketing emails.
A simple dashboard can be a powerful communication tool. Create a "before and after" view. Show the state of data quality and related business metrics before you started, and then display the improvements. Numbers tell a compelling story that leadership understands.
Building a Continuous Feedback Loop
Measuring impact is an ongoing process. Create a continuous feedback loop between your data teams and the business stakeholders who use the data.
This means regular reporting and clear channels for business users to flag data quality issues.
Imagine a sales manager finds that new leads have inaccurate contact info. Your team can trace the problem, build a fix into the cleaning pipeline, and then show the manager how lead conversion rates improved. Data quality becomes a collaborative partnership that helps the business hit its goals.
At DSG.AI, we help enterprises build, deploy, and manage AI solutions where data quality is a foundational, automated part of the process. Our architecture-first approach ensures that from day one, your AI is built on a reliable, scalable, and clean data foundation, turning your data into a true competitive advantage. Discover how we can help you build and operationalize production-grade AI that delivers measurable ROI by exploring our projects at https://www.dsg.ai/projects.


