
Written by:
Editorial Team
Editorial Team
Predictive analytics defines a business question, such as "What will our inventory needs be next quarter?" Machine learning is the engine that finds the answer. It processes large datasets to find patterns invisible to human analysis.
This guide provides a direct roadmap for technology leaders to translate raw data into a measurable competitive advantage.
Translating Data into Strategic Decisions
For a Chief Information Officer (CIO), leadership now relies on data-driven foresight. The primary challenge is not data collection. It is translating existing operational information into clear strategies that improve growth and efficiency. This is the function of combining machine learning and predictive analytics.

This guide provides a straightforward blueprint for implementing these systems. It covers core concepts, scalable architecture, governance, and proving a return on investment (ROI). The goal is to outline a practical path from an initial concept to a fully operational system that generates quantifiable value.
Why This Matters for Technology Leaders
A data-first approach is necessary for competitive positioning. For technology leaders, leading these initiatives means shaping business outcomes directly, not just managing IT. The benefits are specific and address core operational goals.
- Improved Operational Efficiency: These systems can automate complex forecasting tasks. Examples include demand planning in retail or predicting maintenance needs for heavy machinery. This automation reduces manual work and decreases costly errors. For example, a synthetic case shows a logistics company automating email sorting, which reduced manual processing by up to 70%.
- Enhanced Strategic Planning: Access to reliable forecasts of market trends or customer behavior allows an organization to make more confident long-term plans. Resources can be allocated to areas with the highest expected impact.
- Increased Profitability: Using accurate predictions to optimize supply chain logistics, set dynamic pricing, or refine shipping routes directly improves financial performance. For example, some maritime companies have achieved an 8 to 15 percent reduction in fuel consumption against a quarterly baseline by optimizing routes with this technology.
Building a Foundation for Success
Implementing predictive capabilities requires more than algorithms; it requires a clear strategy. The process involves mapping data flows, identifying high-value business problems to solve first, and developing a culture that trusts data-driven insights.
For readers who wish to review the fundamentals, this comprehensive AI guide offers a resource on its broader applications.
The objective is not just to predict the future but to influence it. By anticipating customer needs or market shifts, organizations can act proactively instead of reactively. This creates new opportunities for growth.
This guide is designed to help you build that strategic vision. As shown in our portfolio of enterprise AI projects, a well-defined strategy is the first step toward transforming data into a strategic asset.
How Machine Learning Drives Predictive Models
Predictive analytics is the "what"—the business question about the future. Machine learning (ML) is the "how"—the computational engine that analyzes data to find the answer. ML algorithms learn from historical data to improve the accuracy of future forecasts.
Without ML, predictive analytics is a concept. With ML, it becomes a functional business tool.
This relationship is a core part of how these systems operate. Consider the goal of predicting which shipments are likely to be delayed. This is the predictive analytics objective. The machine learning system analyzes years of shipping data, including weather patterns, carrier performance, and route congestion. It builds a model that can identify at-risk shipments before they depart. The system continuously learns from new shipment data, refining its accuracy over time.
Supervised Learning: Finding Known Patterns
Supervised learning is a common method in business applications. The model is "supervised" by training it on data where the correct outcomes are already known. This is similar to training a new logistics coordinator by providing them with 1,000 past shipment records, each marked as "on-time" or "delayed."
By studying these labeled examples, the algorithm learns to identify the signals that predict delays.
There are two primary types of supervised learning:
-
Classification Models: These models sort data into predefined categories. A common example is a model that classifies incoming customer emails as "Urgent Inquiry," "Standard Question," or "Spam." By learning from how human agents previously tagged emails, it enables support teams to automate prioritization.
-
Regression Models: When a specific numerical value is required, regression models are used. This is the core technology behind demand forecasting, where a model predicts the exact number of units of a product that will sell in the next quarter. It analyzes historical sales figures, seasonality, and marketing budgets to generate a precise numerical forecast.
As a synthetic example, a retail company could train a regression model on three years of sales data, promotional calendars, and local economic indicators. The model might predict that a planned Q4 marketing campaign will generate a 12% to 18% lift in sales for a key product line. This insight allows for more confident inventory planning.
The main advantage of supervised learning is its focus. You ask a specific business question, provide the model with labeled examples, and it learns to make that same decision at scale, with more speed and consistency than a human.
Unsupervised Learning: Discovering Hidden Opportunities
When the specific patterns you are looking for are unknown, unsupervised learning is the appropriate method. Instead of providing the model with labeled data, you give it a raw dataset and ask it to find inherent patterns or groupings.
For example, an analyst could provide the model with a large, unlabeled customer database and ask it to identify natural market segments. The model might uncover a high-value customer group that consistently buys two specific products together in the spring—a previously unknown pattern that can inform a new marketing campaign. This method is also effective for anomaly detection, such as identifying unusual transactions that may indicate fraud or detecting subtle signals of impending equipment failure.
Machine Learning Models for Predictive Tasks
The selection of a model depends on the business question. The table below outlines common models used in enterprise settings and their primary functions.
| Model Type | Business Question It Answers | Example Use Case |
|---|---|---|
| Linear/Logistic Regression | What is the probability of an outcome? Or, what is the expected value? | Predicting customer churn probability based on their usage history. |
| Decision Trees & Random Forests | Which factors are the most important drivers of a specific outcome? | Identifying the top reasons for supply chain disruptions. |
| Gradient Boosting Machines (XGBoost) | How can we get the most accurate prediction possible from complex data? | Forecasting product demand with high accuracy by combining multiple variables. |
| Clustering (e.g., K-Means) | What natural groupings exist within our data? (Unsupervised) | Segmenting customers into distinct personas for targeted marketing. |
| Time Series Forecasting (e.g., ARIMA) | What will this value be at a future point in time? | Predicting future website traffic or quarterly sales revenue. |
| Neural Networks (Deep Learning) | What complex, non-linear patterns exist in very large datasets? | Detecting fraudulent transactions from subtle patterns in transaction data. |
Understanding these core machine learning and predictive analytics approaches helps leaders connect a business challenge to a potential AI solution. The key is to match the correct tool to the specific job.
Architecting for Scalable Predictive Systems
Moving from a successful pilot project to an enterprise-grade system presents a different set of challenges. It requires building a robust technical foundation that can handle real-world operational demands, not just a clever algorithm.
For a CIO or CTO, this means designing an architecture capable of ingesting large data volumes, integrating with existing business software, and delivering reliable predictions consistently.
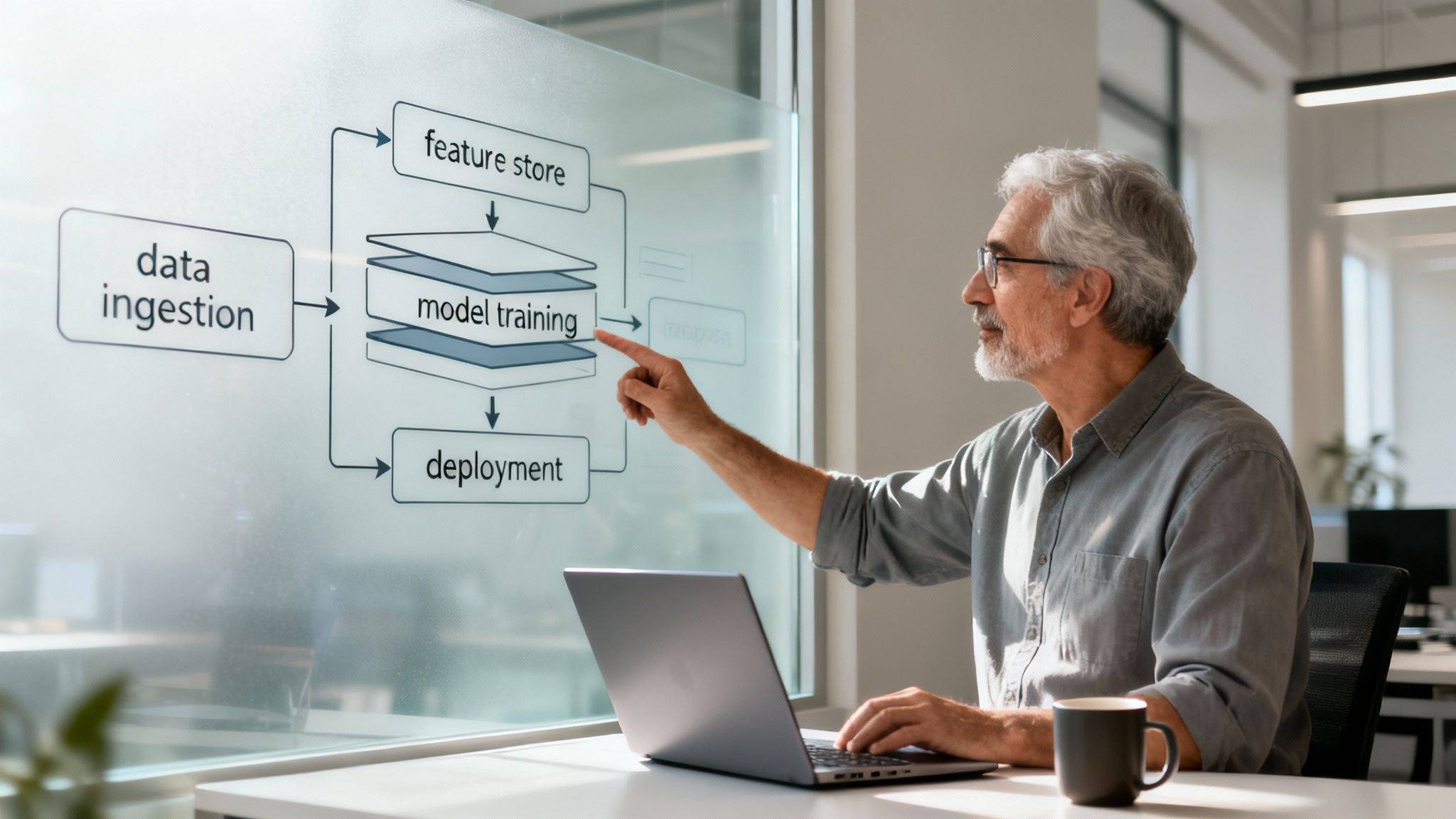
The recommended approach is to define the architecture before selecting the technology. Define what the system needs to do—its functions, integrations, and data flows—before committing to a vendor or platform. This strategy prevents vendor lock-in and ensures the system is adaptable for long-term use.
The growth of the global machine learning market underscores this need. Valued at $17.1 billion in 2021, the market is projected to reach $90.1 billion by 2026, a compound annual growth rate of 39.4%. This growth reflects the deep integration of machine learning and predictive analytics in core business functions, from retail forecasting to equipment maintenance.
Core Components of a Predictive System
A well-architected predictive system functions like an assembly line, converting raw data into actionable intelligence. Each component has a specific function, working together to make the process efficient, repeatable, and scalable. A typical system includes several key layers.
-
Data Ingestion Pipelines: This is the entry point for data. These automated workflows collect raw information—such as transaction logs, sensor readings, or customer clicks—from various business sources and prepare it for processing. They must be robust enough to handle high volumes and diverse data formats.
-
Feature Stores: A feature store is a centralized repository of pre-processed, ready-to-use data elements. For instance, a feature like a "customer's average monthly spend" can be calculated once, stored, and then reused by multiple models. This accelerates development and ensures data consistency.
-
Model Training Infrastructure: This is the high-performance computing environment where data scientists build and refine models. It typically involves cloud resources capable of processing large datasets to test different algorithms and optimize them for accuracy.
-
Deployment and Serving Layer: Once a model is trained, this layer makes it accessible to the business. It could be an API that a logistics platform calls for a real-time delivery estimate, or a batch process that updates inventory forecasts in an ERP system overnight.
Introducing MLOps for Lifecycle Management
Building a model is only the first step. Managing it in a live production environment requires Machine Learning Operations (MLOps)—an operational discipline for managing the entire model lifecycle.
MLOps applies DevOps principles—automation, collaboration, and iteration—to machine learning. It provides a standardized, repeatable process for deploying, monitoring, and retraining models to ensure they remain relevant and accurate as data and business needs change.
This framework addresses questions that arise after a model is deployed. How do we monitor for decreasing prediction accuracy? What is the process for retraining it on new data without causing downtime? MLOps provides the tools and workflows to manage these issues, turning a research project into a reliable business asset. You can learn more in our guide on effective AI orchestration.
Building for scale means looking beyond the algorithm. It requires engineering an end-to-end system that is as robust and manageable as any other core enterprise infrastructure.
Real-World Applications and Measurable ROI
The most important question for CIOs and operations leaders is: what is the tangible business impact? The value of machine learning and predictive analytics lies in how they solve real-world operational problems. The focus should be on delivering quantifiable improvements in efficiency, cost savings, and profit.

By analyzing historical and real-time data, predictive models can forecast future events with enough accuracy to enable proactive decision-making. The result is a meaningful financial return that is reflected in the company's bottom line.
Let's examine how this works in demanding industries.
Optimizing Maritime and Logistics Operations
The global supply chain operates on narrow margins. Small inefficiencies, scaled across thousands of shipments, result in significant cost overruns. Predictive analytics helps identify and mitigate these hidden costs.
Consider maritime fuel consumption. A predictive model can analyze dozens of variables—including ocean currents, weather forecasts, vessel load, and historical route performance—to determine the most fuel-efficient voyage.
For a fleet of cargo ships, this is a significant optimization. A well-implemented model can deliver an 8% to 15% reduction in fuel consumption against a quarterly baseline. Across hundreds of voyages, this translates to millions of dollars in direct savings and a measurable reduction in carbon emissions.
The same principles apply to ground logistics. A common bottleneck is the manual sorting of thousands of emails regarding shipment status, customs holds, or delivery issues.
A machine learning model, trained on a company's past email data, can learn to automatically classify and route these messages with over 95% accuracy. A single application of this type can reduce manual processing time by up to 70%. This frees up the operations team to focus on resolving the actual problems instead of sorting emails.
Driving Efficiency in Agriculture and Retail
Forecasting is essential for agriculture and retail. Inaccurate forecasts can lead to wasted inventory and missed sales. Machine learning brings a higher level of precision to these critical predictions.
For large-scale farming operations, accurately predicting crop yield is vital for planning harvester schedules, storage, and sales contracts.
- Data Inputs: Models ingest a combination of satellite imagery, soil sensor data, weather patterns, and historical yield records.
- Predictive Output: The system generates precise yield forecasts for specific fields.
- Business Impact: This has led to a 20% improvement in forecast accuracy in some projects, which allows for better resource allocation and helps secure more favorable prices from buyers.
Predictive analytics is also impacting retail. The global AI in retail market, valued at $9.97 billion in 2023, is projected to reach $54.92 billion by 2033, driven largely by ML models for inventory and demand. For an operations leader, ML can predict stockouts with 20-30% improved accuracy, which reduces waste and protects profit margins. More on these trends can be found in these machine learning statistics.
Enhancing Retail and Mining Performance
In retail, optimizing a planogram—the placement of products on shelves—is a complex challenge. Predictive models can analyze sales data, customer foot traffic, and product co-purchase data to recommend layouts that increase sales. For instance, a retailer testing an AI-optimized planogram in 50 stores might observe a 5% to 9% sales lift in key categories over a single quarter compared to a control group.
The mining industry sees similar benefits, where profitability depends on optimizing ore extraction. Predictive maintenance models analyze sensor data from heavy machinery to forecast equipment failures before they occur, reducing unplanned downtime by up to 40%. Other models can optimize grinding and separation processes, leading to a 3% to 5% increase in mineral recovery.
In each case, applying machine learning and predictive analytics creates a clear, measurable return on investment.
Navigating Governance and Responsible AI
As machine learning becomes central to business operations, the conversation must expand beyond technology and ROI. Integrating these systems creates new responsibilities. Strong governance, risk, and compliance (GRC) frameworks are essential for building trust and ensuring long-term viability.
Proactive governance should be viewed as a competitive advantage, not a compliance burden.
The Pillars of Responsible AI
Responsible AI is a strategic approach to ensure predictive systems operate ethically, transparently, and fairly. This approach is built on several core principles that should guide the entire process, from data collection to model deployment.
- Fairness: Models must not reinforce or amplify existing biases. This requires auditing datasets for bias and testing model outputs across different demographic groups to ensure equitable outcomes.
- Transparency and Explainability: Stakeholders and regulators need to understand how a model makes its decisions. "Black box" models are a significant liability in high-stakes applications, making explainability a necessary feature.
- Accountability: Clear lines of ownership must be established for the entire AI lifecycle. This includes responsibility for model performance, ethical oversight, and the business impact of its predictions.
- Privacy and Security: Protecting sensitive data is a primary requirement. This includes principles like data minimization and ensuring models do not inadvertently leak private information through their predictions.
A key part of this is understanding and adhering to guidelines for AI GDPR compliance, which sets a standard for data protection.
From Principles to Practice
Implementing these principles is critical, particularly with the emergence of new regulations. In high-stakes fields like healthcare, a model predicting patient decline must be explainable. For compliance officers preparing for regulations like the EU AI Act, this is not optional.
The demand for transparency is driving a market for explainable AI, which is projected to reach $24.58 billion by 2030. Tools that automate GRC are becoming essential for managing these complex requirements.
Integrating Responsible AI is a cultural change, not just a technical one. It requires collaboration between data science, legal, compliance, and business teams to build a shared understanding of risk and a common framework for ethical decision-making.
An effective governance framework requires concrete processes and checkpoints. These include formal model validation steps, automated bias detection scans, and a "human-in-the-loop" for critical decisions. Preparing for these emerging standards is a necessary effort. Our guide to AI Act readiness provides more detail on the requirements.
By addressing governance directly, you can turn a potential risk into a source of trust and a competitive advantage.
Your Implementation Roadmap from Pilot to Production
Transitioning from a pilot project to a production system requires a clear, phased roadmap. This ensures your investment in machine learning and predictive analytics delivers measurable business outcomes. The process should be intentional, focusing on clarity, speed, and long-term value.
It begins with a discovery and data readiness assessment. This phase aligns business goals with high-impact predictive use cases. We analyze your data infrastructure, sources, and quality to identify possibilities and potential obstacles. This initial assessment typically takes one to two weeks and produces a business case and a technical feasibility report.
From Model Development to Continuous Improvement
Once a use case is selected, we begin building the model. This is a focused, agile sprint to create a minimum viable model (MVM) for testing against your actual data. The goal is to demonstrate value quickly. A successful MVM can often show a potential ROI in just four to six weeks, building support for further investment.
After the model proves its value, the focus shifts to deploying it into your live environment and establishing a system for continuous monitoring. This involves integrating the model’s predictions into your core business tools, such as your ERP or logistics platform. MLOps best practices are critical here for tracking accuracy, detecting performance drift, and automatically retraining the model to maintain its effectiveness.
An implementation strategy should prioritize tangible results and full ownership. A structured engagement ensures you receive not just a predictive model, but also the complete intellectual property and source code. This eliminates vendor lock-in and empowers your team to manage the solution long-term.
The entire process must be guided by strong governance principles. This visual illustrates the core tenets.
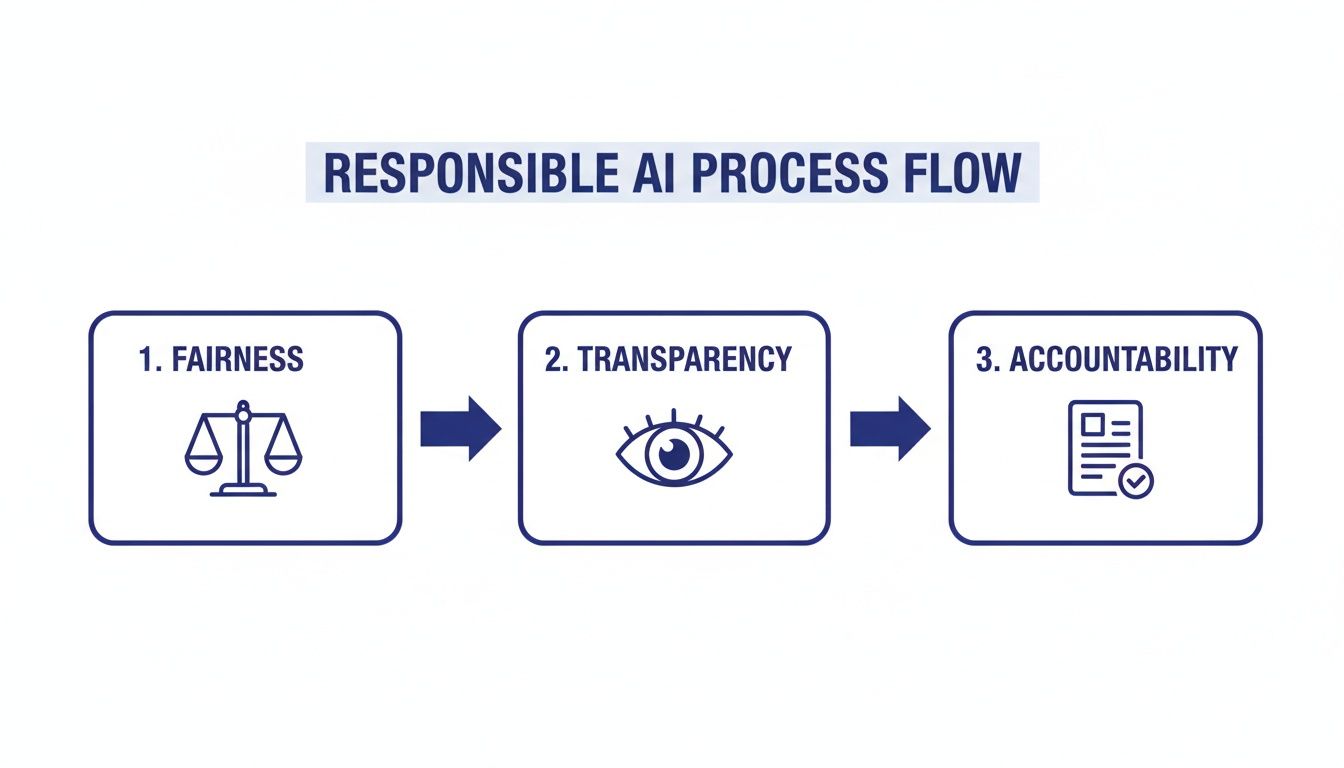
As the flow shows, fairness, transparency, and accountability must be integrated into every stage of the roadmap. By following a structured path that combines rapid development with robust governance, you can confidently move your predictive analytics initiatives from concept to a production system that delivers a competitive edge.
To see how this roadmap could be adapted to your goals, review some of our enterprise AI projects.
Frequently Asked Questions
Leaders exploring machine learning and predictive analytics typically have practical questions. Obtaining clear answers on key differences, realistic timelines, and potential roadblocks is essential before building a business case.
Here are some of the most common questions from enterprise teams.
What's the Real Difference Between Business Intelligence and Predictive Analytics?
Business Intelligence (BI) functions like a rearview mirror. It shows what has already happened. BI dashboards and reports provide a clear view of past performance, answering questions like, "What were our sales in Q2?"
Predictive analytics, in contrast, is like a GPS. It uses historical data to forecast future events. It addresses questions such as, “What are our sales likely to be in Q4, and which factors will influence that outcome?”
It is a shift from describing the past to predicting the future.
How Long Until We Actually See a Return on Investment?
A measurable ROI can be achieved relatively quickly. A tightly-scoped pilot project focused on a single, high-impact business problem can generate tangible results in a short timeframe.
For example, targeted logistics projects focused on automating email classification or optimizing a single shipping route have delivered efficiency gains, such as a 50% reduction in manual processing time, in as little as a six to eight-week engagement. The strategy is to start small and solve a high-value problem first.
What Are the Biggest Risks We Should Watch Out For?
Common risks include poor data quality, "model drift," and a disconnect between the technical team and business stakeholders.
These risks are manageable with a proper plan. Successful projects include:
- A thorough data readiness assessment. Cleaning and validating data sources must occur before model development begins.
- Continuous MLOps monitoring. A model's accuracy can decrease over time as real-world conditions change; this is known as model drift. Effective monitoring detects this early and triggers retraining to maintain performance.
- Early and frequent stakeholder buy-in. Involving business units from the start ensures the model solves a genuine problem and that the end-users will trust and use its outputs.
At DSG.AI, we guide enterprises through these complexities. Our approach is structured and focused on delivering measurable value from the beginning.
Check out our enterprise AI projects to see how we help businesses turn their data into a true competitive edge.


