
Written by:
Editorial Team
Editorial Team
To apply AI for resource optimization, you must first move beyond general goals like "improving efficiency." The initial work involves translating a business objective into a specific, measurable problem that an algorithm can solve. This requires defining a clear target, identifying necessary data, and deciding how to measure success.
Framing Your Optimization Challenge for AI

Before writing any code, the critical first step is to define the problem you are trying to solve. An AI model is a powerful tool, but it is ineffective without a well-defined target. Vague goals often lead to unfocused projects that consume resources without delivering business value.
The goal of this initial framing stage is to create a clear, quantifiable link between a business problem and a technical solution. This is where most AI projects are set up for success or failure. It requires a partnership between business stakeholders, who understand the operational pain points, and technical teams, who know AI's realistic capabilities.
Pinpointing High-Impact Areas
First, you need to identify which parts of the business have the most to gain. Resource optimization is not about addressing every minor inefficiency; it is about targeting areas with the largest potential return.
Based on our experience, enterprises typically find the most value in these areas:
- Production Scheduling: Adjusting machine usage and job sequencing to reduce downtime and increase asset output.
- Logistics Routing: Designing delivery routes to cut fuel costs, shorten travel times, and meet delivery windows.
- Workforce Allocation: Aligning staff schedules with demand forecasts, skill sets, and labor rules to avoid over- or under-staffing.
- Inventory Management: Using predictive models to maintain optimal stock levels, avoiding both excess inventory costs and stockouts.
To understand real-world allocation challenges, it can be useful to look at how other industries approach them. For example, the complex field of crew resources management in aviation offers parallels for framing your own challenge.
Translating Business Goals into AI Problems
Once you have identified a high-impact area, the next step is to translate that business goal into a formal machine learning problem. This involves specifying the inputs, the desired outputs, and the metrics for success.
Key Takeaway: The success of an AI project is not measured by its technical sophistication. It is measured by its ability to solve a specific, well-defined business problem. Without a clear objective and measurable KPIs, even the most advanced algorithm is an experiment.
Let's review a synthetic example to make this concrete.
Synthetic Scenario: A Manufacturer's Scrap Reduction Goal
A manufacturing firm is losing money from excessive scrap material on its production line. Leadership sets a business goal: reduce scrap by 8 to 15 percent compared to the Q2 baseline. "Reduce scrap" is not a problem you can give to an AI; it needs to be framed correctly.
Here is how to break that down:
-
Define the Output (Target Variable): The model needs something to predict. In this case, the target is the predicted scrap percentage for a given production run. This is a clear, numerical output.
-
Identify Input Variables (Features): What factors influence scrap production? The team would identify and collect data on key inputs for the model:
- Raw material specifications (e.g., viscosity, purity)
- Machine settings (e.g., temperature, pressure, speed)
- Environmental conditions (e.g., ambient humidity)
- Operator shift data (e.g., which team was on duty)
-
Establish a Success Metric: The model's technical performance will be judged on its accuracy in predicting the scrap percentage. However, the business ROI will be measured by the actual reduction in scrap material after the plant uses the model’s recommendations to adjust machine settings.
By framing the problem this way, the team has a clear plan. They are building a predictive tool designed to achieve a specific financial target.
This foundational work is essential before starting data collection and model development. For leaders, a structured process can help identify valuable AI opportunities within operations. You can learn more by exploring how to assess your AI readiness and build a solid foundation.
Building the Data Foundation for Your AI Models
An AI model is only as effective as the data it is trained on. For resource optimization, establishing the right data foundation is the most critical factor for project success. Without the right data, even a sophisticated algorithm is not reliable.
Think of it as gathering ingredients for a recipe. Your model needs a diverse range of information to understand your operation and make accurate predictions.
Gathering the Essential Data Types
The specific data you need will depend on the problem you defined. For most enterprise resource optimization projects, data falls into a few key categories:
- Historical Performance Logs: This is the foundation. It includes machine uptime, production output, past delivery times, and workforce schedules. This data provides the historical context for the model to learn what works.
- Real-Time Sensor Data: For physical operations, data from IoT sensors is valuable. This can include machine temperatures, conveyor belt speeds, or vehicle GPS locations. Real-time data allows the model to react to current conditions.
- Supply Chain and External Feeds: Your business is part of a larger system. Data from suppliers, weather forecasts, or market demand signals can provide external context that improves model accuracy.
Obtaining this data is the first challenge. The next is ensuring its quality.
Tackling Common Data Quality Issues
Raw operational data is often messy, containing errors, inconsistencies, and gaps that can mislead an AI model. These issues must be addressed.
We frequently see the following problems:
- Missing Values: A sensor goes offline, or an operator forgets a log entry. You will need a strategy for this, such as filling gaps with an average value (mean imputation) or using more advanced techniques to estimate the missing information.
- Inconsistent Formats: One system might log dates as MM/DD/YYYY, while another uses DD-MM-YY. These differences must be standardized before the model sees them.
- Outliers: A faulty sensor might record an impossible temperature, or a typo could create an inaccurate inventory count. These outliers can skew what the model learns and need to be identified and either corrected or removed.
A common rule in data science is that you can spend up to 80% of a project's time preparing and cleaning data. Investing this time upfront prevents rework later and ensures your model is built on accurate information.
Once your data is clean and consolidated, you need a plan for storage and processing.
Choosing Your Technical Architecture
The technical architecture is the backbone of your AI initiative. It must be scalable, reliable, and able to handle data flow from various sources. The main decision is between a cloud platform and an on-premise solution.
| Architectural Approach | Key Strengths | Best Suited For |
|---|---|---|
| Cloud-Based Platforms | Scalability, managed services, lower upfront cost, access to pre-built AI tools (e.g., AWS SageMaker, Google AI Platform). | Organizations that need speed, flexibility, and want to avoid managing physical infrastructure. |
| On-Premise Solutions | Full control over data security, potential for lower long-term costs, compliance with strict data residency rules. | Enterprises with highly sensitive data, existing data center investments, or specialized hardware requirements. |
Whichever path you choose, a few core components are essential:
- Data Lake: A central repository for storing large amounts of raw, structured, and unstructured data from all your sources.
- ETL Pipelines: "Extract, Transform, Load" pipelines are automated processes that pull data from its source, clean it, and load it into a central location for analysis. For complex use cases, effective data and AI orchestration is critical for managing these workflows.
- Data Warehouse: A structured repository that stores cleaned, processed data. It is optimized for fast querying by BI tools and AI models.
Building this foundation is a significant undertaking, but it is the only way to ensure your AI-driven optimization efforts are sustainable, scalable, and capable of delivering measurable business value.
Selecting the Right AI Optimization Model
With a clean data foundation in place, you can focus on the AI model that will drive your resource optimization. This is where strategic goals are translated into mathematical execution. The objective is not to use the most complex algorithm but to find the best fit for your operational challenge.
The range of available models is broad, from classic deterministic methods to adaptive intelligent agents. For stable environments with fixed constraints, such as a factory with fixed machine capacities, traditional approaches like linear programming can be effective. These models are good at finding the single best solution when all rules are known.
However, many business environments are not stable. This is where more advanced AI techniques are valuable.
Matching the Model to the Problem
An effective AI implementation starts with assessing which modeling family fits your use case. Not all algorithms are the same, and this choice directly impacts the quality of your results.
Here are the most common approaches we use:
- Linear and Integer Programming: These are suitable for problems with well-defined constraints and a single objective, like minimizing costs in a logistics network with known shipping capacities. For static problems, they are robust and computationally efficient.
- Supervised Machine Learning: Models like gradient boosting or random forests are effective for prediction. An example is predicting equipment failure from sensor data. This allows for proactive maintenance, optimizing technician time and asset uptime.
- Reinforcement Learning (RL): This is used for dynamic, complex environments where the best action changes with real-time conditions. An RL agent learns from trial and error, making it suitable for challenges like dynamic pricing, energy grid management, or robotic warehouse navigation.
To illustrate, let's review a past client scenario.
A Logistics Company Case Study
We worked with a logistics company aiming to cut fuel consumption and improve on-time delivery rates for its fleet of 200 trucks. Initially, they used a solver-based approach (a form of linear programming) to plan routes daily. It was functional but could not adapt to real-world events like traffic, accidents, or road closures.
We piloted a reinforcement learning agent for a subset of their fleet.
The RL agent, unlike the static solver, was trained in a simulated environment with historical traffic data, weather patterns, and delivery time constraints. It learned to make sequential, turn-by-turn decisions to maximize a "reward" function combining minimal fuel use with on-time arrivals.
After a three-month pilot, the results were clear. The RL agent delivered a 12% reduction in fuel costs and a 15% improvement in on-time deliveries compared to the routes from the traditional solver. The key was the model’s ability to adapt in real time by rerouting trucks based on live traffic feeds, a capability the static model lacked.
The following table breaks down common modeling approaches for resource optimization.
Comparison of AI Modeling Approaches for Resource Optimization
This table compares common AI and machine learning techniques for resource optimization, highlighting their typical use cases, complexity, and primary benefits.
| Modeling Approach | Best For | Complexity | Key Benefit |
|---|---|---|---|
| Linear/Integer Programming | Static, well-defined problems with clear constraints (e.g., supply chain network design, production scheduling). | Low to Medium | Provides a provably optimal solution for stable environments. Highly interpretable. |
| Supervised Learning | Predictive tasks where historical data can inform future outcomes (e.g., demand forecasting, predictive maintenance). | Medium | Excellent at identifying patterns and making accurate predictions to inform resource allocation. |
| Reinforcement Learning (RL) | Dynamic, interactive environments requiring sequential decision-making (e.g., real-time fleet routing, dynamic pricing). | High | Learns and adapts to changing conditions, finding optimal strategies in complex, unpredictable systems. |
| Simulation Modeling | "What-if" analysis and system-level understanding (e.g., modeling factory floor layouts, testing inventory policies). | Medium to High | Allows for risk-free testing of different strategies before real-world implementation. |
Each of these methods is useful. The key is to avoid using an advanced tool when a simpler, more robust one is sufficient.
The Model Development Lifecycle
Regardless of the model chosen, the development process follows a structured lifecycle of feature engineering, training, and validation. This phase requires data science rigor to ensure the model performs reliably in a real-world environment. This process also depends on the architectural decisions made earlier.
This decision tree illustrates how factors like data quality and scale influence the choice between on-premise and cloud solutions for your AI data foundation.
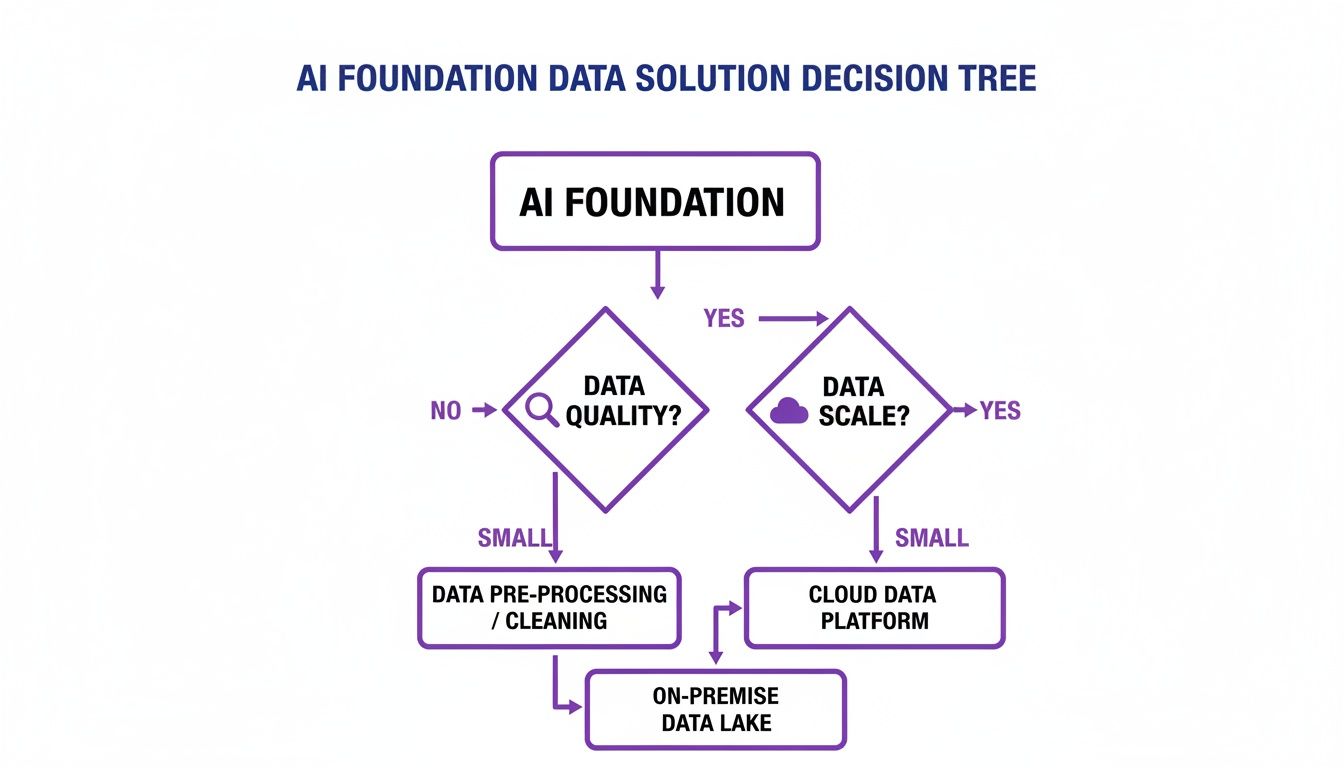
As the visualization shows, practical constraints often lead teams toward scalable cloud solutions or on-premise setups that offer greater control over data quality.
The pressure to get this right is significant. Driven by efficiency targets and supply chain volatility, companies are modernizing their operations. A recent industry survey found that 93% of leaders rated increasing operational efficiency as a top priority. You can find more of these findings in the 2025 Digital Trends in Operations survey from PwC.
Finally, choosing the right performance metrics is the last critical step. A model can have high technical accuracy but fail to create business value. Always select KPIs that directly reflect your operational goals, such as cost per unit shipped or asset utilization percentage. This ensures that model improvements translate directly to financial results.
From Model to Operations: Deployment and Monitoring

An AI model in a development environment provides no business value. It must be integrated into daily operational workflows. This is the transition from a functional model to a live, value-creating system.
Successful AI deployment is about making its insights actionable for your team. The goal is to embed the model’s recommendations into existing processes so they become a natural part of decision-making. This requires a plan for how, when, and where the AI's output reaches the people who need it.
Choosing the Right Deployment Pattern
How you deploy your model depends on the operational problem you are solving. The deployment pattern must match the speed and frequency of the decisions your business needs to make.
Most enterprise use cases fall into one of two patterns:
- Real-Time APIs: This is for dynamic, fast-paced environments. For example, a dynamic pricing model for an e-commerce site needs to provide a price recommendation in milliseconds every time a user visits a product page. In this scenario, the model is exposed via an API that the website can call on demand.
- Batch Processing: This approach is better for decisions made on a recurring schedule. A weekly inventory planning model does not need to run every second. It can process the previous week's sales data in a batch job every Monday morning to generate replenishment orders.
Your choice here affects your architecture and costs. Real-time APIs require low-latency infrastructure, while batch processing can run on less expensive, non-urgent compute resources.
Integrating with Your Core Enterprise Systems
A model’s recommendations are useless if they remain in a data scientist's notebook. For true optimization of resources, those insights must flow directly into the systems your teams already use. This is key to driving adoption and ensuring the model’s output leads to action.
Your Enterprise Resource Planning (ERP) system is often the primary target. If your AI model suggests an adjusted production schedule, that new schedule should automatically appear in the ERP. The shop floor manager sees the updated plan without needing a separate dashboard. For a related example, see how AI voice recognition in healthcare models integrate directly with clinical systems.
Monitoring for Performance and Model Drift
Deploying the model is not the final step. It is the beginning of a continuous cycle of monitoring and maintenance. All models degrade over time in a process called model drift. The real-world conditions the model was trained on will change, causing its predictive accuracy to decrease.
Key Insight: Without active monitoring, a model that initially delivered a 15% efficiency gain could see its performance drop to 5% within six months as market conditions shift. Sustained value requires sustained monitoring.
To address this, you must set up robust monitoring from the start. This means creating dashboards that track two types of metrics:
- Business KPIs: These measure the actual business impact. Are you still seeing the expected reduction in fuel costs? Is asset utilization still high? These are the numbers that matter to leadership.
- Model Performance Metrics: These are technical health checks, like prediction accuracy or error rates. A sudden increase in prediction error is often the first sign of model drift and the need for retraining.
This focus on operational performance is a central theme in corporate strategy. A synthetic analysis of corporate resource-management practices between 2023 and 2025 shows a shift toward prioritizing capacity planning. In a synthetic 2025 industry survey, 60% of companies reported targeting higher resource utilization. Despite this focus, only 16% planned to implement more advanced resource-management software.
Deploying and monitoring an AI system is an ongoing process. By selecting the right deployment pattern, integrating with core systems, and monitoring for model drift, you ensure your AI investment delivers durable, measurable value.
Governance, Compliance, and Measuring True ROI
Using an AI system to optimize resources brings new responsibilities. Governance is not just a legal exercise; it is the foundation for building trust, managing risk, and ensuring your AI efforts are responsible and sustainable.
As AI becomes more embedded in critical business operations, regulators are paying attention. Frameworks like the EU AI Act are setting rules for transparency, explainability, and AI risk management. This means you need a plan for documenting how your models make decisions, what data they are trained on, and how those decisions affect your business. Being unprepared can lead to fines and reputational damage.
Creating an Internal Governance Framework
To manage this new reality, you need a formal governance structure. A good starting point is to form an internal AI governance committee. This should be a cross-functional team with leaders from legal, compliance, data science, and business operations.
This committee has several critical responsibilities:
- Setting AI Policies: They need to create clear internal rules on the ethical use of AI, data privacy standards, and model validation before deployment.
- Assessing Risk: They will be responsible for evaluating the potential risks of each AI project, from operational disruptions to unintended bias in model outputs.
- Defining Documentation Standards: This group must mandate thorough documentation for every model, covering its training data, architecture, and performance benchmarks.
This proactive work not only prepares you for new regulations but also builds confidence across the company that your AI systems are sound. If you are looking for a structured way to begin, understanding the path to EU AI Act readiness offers a practical blueprint for building a governance program.
A Concrete Framework for Measuring ROI
Governance ensures responsible operation, but leadership will ask about the return on investment. You need a data-driven framework to demonstrate the tangible business value your resource optimization AI is delivering.
This starts by defining specific, measurable Key Performance Indicators (KPIs) before the project begins. These should not be generic metrics; they must tie directly to the business problem you defined at the start.
Key Takeaway: Real ROI is not measured in model accuracy scores—it is measured in operational improvements. Your report to leadership should highlight metrics like cost reduction percentages and asset utilization gains, drawing a direct line from the AI implementation to business results.
To build a compelling business case, your reporting must show a clear before-and-after picture. This involves three steps:
- Establish Your Baseline: Before the AI system is live, capture performance data for at least one full business cycle. This is your control group.
- Track Post-Implementation Performance: Once the model is running, monitor the same KPIs.
- Calculate the Lift: The difference between your baseline and the new performance numbers is your ROI. Present this as a percentage improvement or a dollar figure.
For instance, a logistics company could report a 12% reduction in fuel consumption per route compared to the Q2 baseline. Translating this into $1.2 million in projected annual savings is what gets attention.
This rigorous measurement is not just for corporate technology. A parallel can be found in how the public sector handles large-scale reserve and asset management. For example, the World Bank's 2025 Reserve Management Survey, which gathered responses from 136 central banks, highlights how systematic, data-driven frameworks are used to optimize large financial outcomes. You can learn more about these global reserve management practices to see these principles in action globally.
By combining robust governance with a disciplined ROI framework, you ensure your AI-driven resource optimization is effective, compliant, and demonstrates its value to the organization.
Common Questions on AI Resource Optimization
When starting with AI for resource optimization, practical questions arise. Based on our experience helping companies, here are some of the most common questions and our answers.
What Are the Most Common Pitfalls to Avoid?
The path to AI-driven efficiency has potential pitfalls, most of which are strategic, not technical.
One of the most frequent mistakes is poor problem framing. A vague goal like "improve efficiency" is not something a machine learning model can solve. You must translate that business goal into a specific, measurable problem.
Another common error is underestimating the data work. Teams may be excited about modeling, but cleaning, integrating, and preparing data can take up to 80% of the project timeline. Rushing this step will result in unreliable models.
Finally, do not forget operational buy-in. You can build a technically perfect model, but if the people who are supposed to use it do not trust it or understand its recommendations, it will not be adopted.
How Long Until We See a Return on Investment?
The answer depends on your project's scope and data readiness. A well-defined pilot project can show tangible value within six to nine months.
For a full, enterprise-wide rollout, you are more likely looking at 12 to 18 months to see a major financial return. The key is to start with a focused pilot that targets a high-impact, manageable problem. This allows you to prove the concept quickly and build momentum.
Our Experience: Starting with a focused, high-impact pilot with clear success metrics is the most effective way to prove value quickly. It secures executive buy-in and paves the way for scaling the program.
Do We Need a Large Team of Data Scientists to Start?
No. In fact, starting too large can be a mistake. Many successful AI initiatives begin with a small, focused team of two or three key people.
This pilot team usually includes:
- A data scientist for modeling and validation.
- A data engineer to build the data pipelines.
- A business domain expert who understands the operational side and can ensure the solution works in the real world.
It is better to start small, prove value with a specific use case, and then scale your team and investment once the ROI is clear. You can also use partners and cloud AI platforms to start faster without a large hiring commitment.
How Do We Ensure the AI Is Trusted and Adopted?
Adoption depends on trust and utility. The best way to build both is to involve your end-users from day one. Build the solution with them, not for them. This ensures it solves their actual problems and fits into their existing workflows.
Using explainable AI (XAI) techniques is also beneficial. These methods show why the model is making a certain recommendation. When people can see the logic, they are more likely to trust it.
A good way to start is to run a pilot where the AI acts as a co-pilot. The system makes recommendations, but a human expert has the final say. This approach builds confidence and makes the transition to more automated workflows feel natural and safe.
At DSG.AI, we help enterprises navigate these questions every day. Our architecture-first approach ensures your AI solutions are built on a solid foundation, delivering measurable business value from day one. See how we turn complex operational challenges into competitive advantages by exploring our work.
Find out more about our enterprise AI projects.


