Written by:
Editorial Team
DSG.AI
In artificial intelligence, inferencing is the operational phase where a trained model applies its knowledge to make predictions on new data. If training an AI model is like a student studying a subject for years, inferencing is the final exam where the student uses that knowledge to solve problems they have not seen before.
This is the point where an AI model begins to provide business value.
From Learning to Doing: The Role of AI Inferencing
AI inferencing is the process of using a trained neural network to make a prediction. It turns a static model—a file containing learned patterns—into a practical tool for decision-making. After a model is trained on large datasets, a computationally intensive process, it becomes ready for deployment. This deployment phase is where inferencing occurs.
When a voice assistant answers a question, a streaming service provides a movie recommendation, or a translation app converts text, you are witnessing AI inferencing. The model receives a new input—your voice, browsing history, or text—and uses its learned patterns to generate a prediction.
AI Training vs. AI Inferencing: A Fundamental Contrast
To understand inferencing, it is useful to compare it with its counterpart, AI training. These two phases of the AI lifecycle have different goals and resource requirements.
Here is a breakdown of the distinction.
AI Training vs AI Inferencing At a Glance
This table compares the two primary phases of the AI lifecycle, highlighting their distinct goals, processes, and resource needs.
| Aspect | AI Training | AI Inferencing |
|---|---|---|
| Primary Goal | To learn patterns from a large dataset. | To apply learned patterns to new data. |
| Data | Uses large, labeled datasets. | Uses single, unlabeled data points or small batches. |
| Computation | Extremely compute-intensive; can take days or weeks. | Lighter and faster; designed for real-time responses. |
| Output | A trained model file (e.g., weights and biases). | A prediction or decision (e.g., a classification, a number). |
| Frequency | Done once or periodically to update the model. | Happens continuously, potentially millions of times per day. |
Training is an occasional investment to create the model, while inferencing is the continuous work the model performs.
Inferencing is where the investment in training is converted into measurable business outcomes. For example, a single trained fraud detection model might perform billions of inferences over its lifetime, each one representing a decision to approve or deny a transaction.
Why Inferencing is Gaining Attention
As AI integrates into business operations, the industry's focus has shifted toward making the inferencing step more efficient. A model may be trained once per quarter, but it could be asked to perform billions of inferences.
This operational demand has created a significant market. The global hardware sector for AI inferencing was valued at over $15 billion in 2023 and is projected to exceed $40 billion by 2027, according to market analyses from firms like Grand View Research. This growth shows the business focus on deploying AI that is fast and cost-effective.
Understanding the fundamentals of AI inferencing is easier with a broader knowledge of AI and Machine Learning services that support these applications. This context clarifies how the inferencing stage fits within a larger strategy to build and deploy intelligent systems.
How AI Models Make Real-World Predictions
A trained AI model is ready to make predictions on new, live data. This process, inferencing, transforms an AI model from a theoretical exercise into a practical tool.
Let's consider a synthetic example: an AI model designed to identify animals in photos. When it receives a photo of a cat, the model processes a grid of pixels, each with a numerical color value.
The Journey Through a Neural Network
First, the model must prepare the data. This step, preprocessing, converts the raw pixel information into a standardized format the neural network can use. Once processed, the data begins a forward pass, traveling layer by layer through the network.
The initial layers of neurons identify basic features like edges, corners, and color gradients. As the data moves deeper into the network, subsequent layers combine these simple features into more complex concepts, like whiskers, fur texture, or the shape of an ear.
Each neuron activates based on the patterns it was trained to recognize, passing its output to the next layer. Finally, the output layer assembles the information to make a final prediction, assigning a probability score to labels such as "cat," "dog," or "rabbit."
This is how a model transitions from learning to execution.
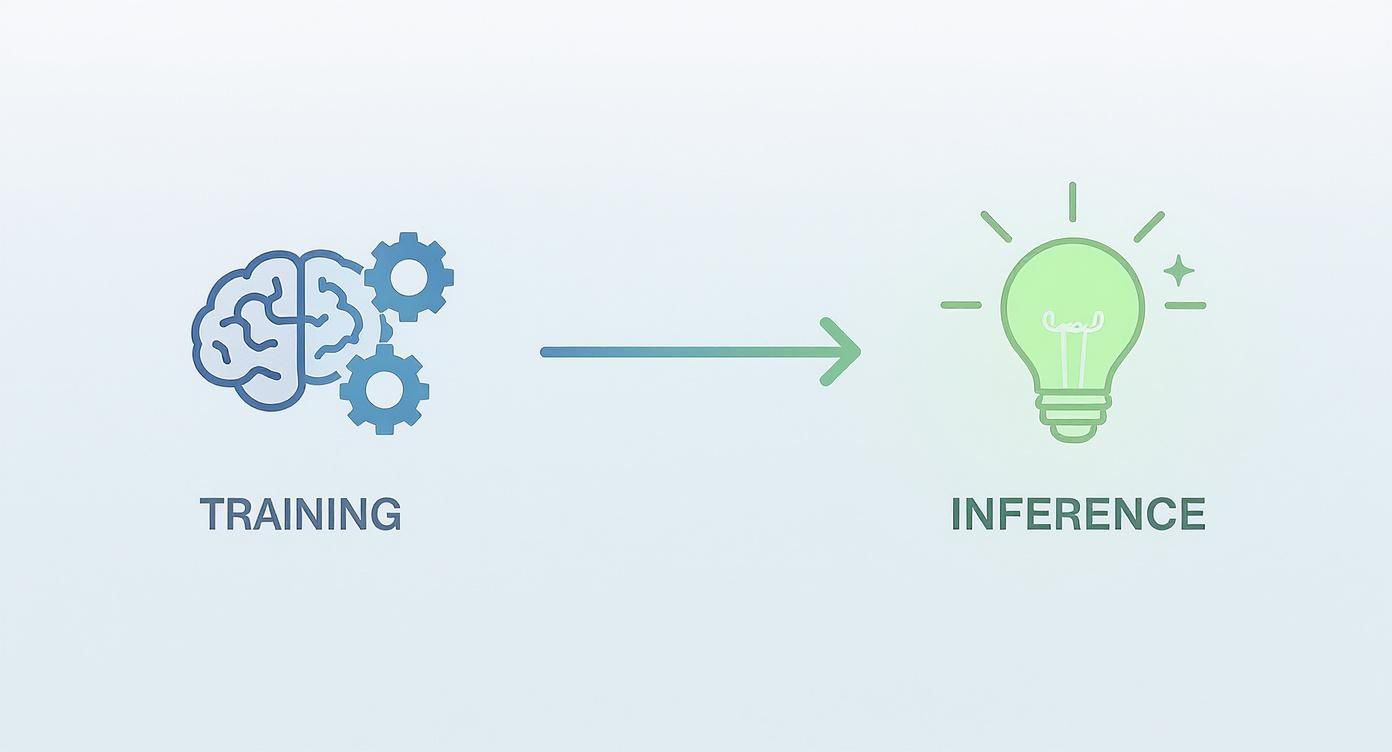
The diagram above illustrates the two phases of the AI lifecycle: the resource-intensive training phase (the brain) and the streamlined, application-focused inference phase (the lightbulb) where the model provides value.
Real-Time vs. Batch Inferencing
The optimal approach to inferencing depends on the business problem. Methods fall into two main categories: real-time and batch. The choice between them is fundamental to a successful AI deployment.
Real-time inference (also called online inference) prioritizes speed. It processes a single piece of data as it arrives, aiming for a near-instantaneous result. This is necessary for applications where low latency is critical.
- Fraud Detection: Analyzing a credit card transaction as it occurs to approve or decline it in under 200 milliseconds.
- Live Video Analysis: Identifying an object in a live security feed to trigger an immediate alert.
- Voice Assistants: Transcribing spoken words into text in real-time to provide a quick response.
Batch inference, by contrast, is designed for efficiency at scale. It collects data over a period and processes it all at once. This is the preferred method for large-scale tasks where immediate results are not required.
- Sales Forecasting: Analyzing a full month of sales data to predict the next quarter's revenue.
- Customer Segmentation: Grouping millions of customers based on their annual purchasing habits.
- Medical Imaging: Processing hundreds of patient X-rays overnight to flag potential anomalies for a radiologist's review the next morning.
The choice between real-time and batch inferencing is a strategic trade-off between the immediate value of a single prediction and the operational efficiency of processing millions.
The reliability of AI inferencing in computer vision has improved significantly. A key moment occurred in 2012 when a Google deep neural network in the ImageNet competition reduced the error rate from 26% to 15%. By 2020, newer models had reduced the error rate to below 5%. This increased accuracy has fueled a large market; the global AI inferencing sector for computer vision was valued at $12 billion in 2022 and continues to grow. You can find a history of these AI milestones and how they have shaped current technology.
Optimizing AI Models for Efficient Inferencing
An accurate AI model's real-world value depends on more than correct answers. If the model is too slow, too large, or too expensive to run, its practical utility is low. The central challenge of AI in production is bridging the gap between a trained model and an efficient, cost-effective application. This is achieved through optimization.
Optimization refines a model to remove unnecessary complexity so it can operate with maximum efficiency. This step makes it possible to run sophisticated AI on a smartphone or power an application that requires an immediate response.
The Balancing Act of Speed and Accuracy
Every optimization technique involves a trade-off. Making a model faster or smaller often results in a slight decrease in predictive accuracy. The goal is to find the optimal balance for a specific use case. For example, a model built to predict customer churn might accept a 1-2 percentage point drop in accuracy if it leads to a 40% reduction in cloud computing costs.
Conversely, an AI tool for medical diagnostics would require the highest possible accuracy, even at a higher operational cost. As you work to improve model performance, you will navigate this dynamic. For further reading, understanding the AI speed-accuracy trade-off offers a framework for these decisions.

Core Techniques for Model Optimization
Engineers use a toolkit of techniques to prepare models for production. Each one addresses the model's structure from a different angle.
Model Quantization
Quantization reduces the numerical precision of a model’s weights—the parameters learned during training. Instead of using high-precision 32-bit floating-point numbers for calculations, quantization converts them to simpler formats, like 8-bit integers.
This change can reduce a model's file size by up to 75% and increase computation speed, as processors handle integer math more quickly than floating-point math. There is usually a small reduction in accuracy, but for many applications, the performance gain is significant.
Model Pruning
Model pruning removes redundant connections (weights) within a neural network that contribute little to the final prediction, often because their values are close to zero. This is analogous to a bonsai artist trimming small branches to reveal the tree's essential form.
Pruning creates a "sparse" model that is smaller and requires less computation. It is common to reduce a model's complexity by 50% or more, leading to faster inference and lower memory requirements without a significant loss in performance.
Knowledge Distillation
Knowledge distillation uses a "teacher-student" process. It starts with a large, highly accurate but slow "teacher" model. A smaller, more efficient "student" model is then trained to mimic the teacher's outputs.
Instead of learning from the raw data, the student learns from the teacher, absorbing its learned patterns into a more compact form. This allows for the deployment of a lightweight model that retains most of the original’s accuracy, making it suitable for devices with limited resources, such as phones or IoT sensors.
These methods are standard tools for making models production-ready.
Common AI Inference Optimization Techniques
The table below summarizes these core optimization methods, outlining what each one does and the trade-offs involved.
| Technique | Primary Goal | Key Trade-Off |
|---|---|---|
| Quantization | Reduce model size and accelerate computation by lowering numerical precision. | A slight, often acceptable, decrease in predictive accuracy. |
| Pruning | Decrease model complexity and size by removing redundant neural connections. | Can impact accuracy if too many connections are removed. |
| Distillation | Create a smaller, faster model that mimics a larger, more accurate one. | The student model's accuracy is high but may not perfectly match the teacher's. |
By applying one or more of these techniques, organizations can ensure their AI models are practical, efficient, and valuable in production environments.
Choosing Your Inference Deployment Strategy
An optimized AI model is ready for deployment. The next decision is where it will run. This is a strategic choice that impacts performance, cost, and application design. This is the deployment strategy.
The location where a model performs inference shapes user experience and data privacy. The three main strategies are deploying to the cloud, running on the edge, or using a hybrid model.

Cloud Inferencing: Power and Scale
Cloud inferencing means your model runs on servers in a data center managed by providers like AWS, Google Cloud, or Azure. It is a common choice for large-scale applications that require significant computational power and the ability to scale resources on demand.
The process involves an application sending new data over the internet to the cloud, where the model makes a prediction, and the result is sent back. This round trip creates latency, so it may not be suitable for applications that need an instant response. However, for applications that can tolerate a slight delay, the computational power of the cloud is a major advantage.
Cloud inferencing is a good fit for:
- Recommendation Engines: Processing millions of user interactions to power product suggestions on an e-commerce site.
- Large Language Models (LLMs): Driving chatbots and content generation tools that require substantial processing power.
- Complex Financial Modeling: Executing risk assessments on large historical datasets.
The primary benefit is scalability. If the user base doubles, you can provision more resources without purchasing new hardware.
Edge Inferencing: Speed and Privacy
Edge inferencing runs the model directly on the end-user's device, such as a smartphone, a car's computer, or a factory sensor.
This approach moves computation as close to the data source as possible. The two main advantages are low latency and enhanced data privacy. Since data does not need to leave the device, it is a suitable solution for handling sensitive information or for scenarios with intermittent internet connectivity.
Edge deployment enables real-time applications. By eliminating the network round trip, it supports use cases where a split-second delay is critical, from autonomous driving to interactive augmented reality.
Examples of edge inferencing include:
- On-Device Facial Recognition: Unlocking a phone happens instantly because the biometric data is processed locally.
- Industrial IoT: A sensor on a manufacturing line identifies a product defect in real-time and triggers an alert.
- Smart Security Cameras: Identifying a person at a doorstep without streaming video to the cloud.
The trade-off is that edge devices have limited computational power and memory. This is why the optimization techniques discussed earlier are critical for an edge strategy.
Hybrid Inferencing: A Combined Approach
A hybrid strategy combines cloud and edge computing. It is based on the idea that some tasks require the immediate response of the edge, while others need the processing power of the cloud.
In a hybrid setup, a smaller model on an edge device handles time-sensitive tasks. For more complex analysis, the device can send select data to a larger model in the cloud. This tiered system allows for a balance between performance, cost, and capability. For example, a smart camera might use an edge model to detect motion and then send that specific video clip to the cloud for more detailed object recognition.
Managing these distributed systems requires a solid understanding of effective AI orchestration to maintain reliability at scale. This allows a team to manage the entire lifecycle of models, regardless of their location.
Measuring AI Inference Performance
Once an AI model is deployed, its success is measured by operational performance. An accurate model is not useful if it cannot deliver results quickly, handle the required workload, or operate within a budget. These metrics define an AI system's viability.
These are not just technical benchmarks; they are indicators of business value. They show how an AI system is performing its job and impact user satisfaction and the bottom line.
Latency: The Need for Speed
Latency is the time it takes for a model to provide a response after receiving data. It is the "time to prediction," usually measured in milliseconds (ms). For applications with human interaction, low latency is critical.
For a fraud detection system, a delay of a few hundred milliseconds at checkout is unacceptable. According to Google/Deloitte research, a 100-millisecond delay on a retail mobile site can reduce conversion rates by 7%. The same principle applies to AI features; slow performance is often perceived as a system failure.
Throughput: Handling the Workload
While latency measures the speed of a single prediction, throughput measures how many predictions the system can produce over a set period. The standard metric is inferences per second (IPS). This is important when processing a large volume of data.
For example, a content moderation AI on a social media platform must scan thousands of images and comments every second. High throughput ensures the system can keep up with the data influx. A system designed for high throughput might not have the lowest latency for a single request but can process large volumes efficiently.
The core operational challenge of AI inferencing is balancing latency and throughput for a specific use case. Optimizing for one often involves a trade-off with the other.
Cost: The Financial Bottom Line
Every prediction has an associated cost. Cost is the measure of what is spent to run a single inference. This includes cloud compute bills for GPU or CPU time, as well as the amortized cost of on-premise servers, power, and cooling. This is often tracked as cost per inference or cost per million inferences.
The trade-offs are clear here. Using more powerful—and expensive—hardware to reduce latency will increase the cost per inference. Alternatively, processing data in large batches can maximize throughput and lower the average cost but will likely increase latency for any individual request. For most businesses, meeting a target cost-per-inference is as critical as meeting performance goals.
Understanding these interconnected metrics is the first step in building a sustainable AI strategy. Before scaling models, you need a clear picture of their operational performance. You can learn more about how to evaluate AI systems in our guide to assessing AI models and their business impact. This knowledge helps you make informed decisions about hardware, optimization, and deployment that align with financial and operational goals.
Best Practices for Enterprise AI Inferencing
Deploying an AI model in a production environment requires a focus on operations. Success is not measured solely by a model's accuracy score; it is determined by building an AI inferencing pipeline that is reliable, scalable, and cost-effective. Establishing a set of best practices from the beginning can help avoid common failures and achieve a return on AI investment.
The most important starting point is to design with deployment in mind. Teams sometimes build large, state-of-the-art models only to find they are too slow or expensive to run in the target environment. The final deployment location—whether a small edge device or a large cloud server—should be considered from the initial design and training phases.
Build a Robust MLOps Foundation
Once a model is live, its management is ongoing. To manage AI systems at an enterprise scale, a strong MLOps (Machine Learning Operations) foundation is necessary. This framework automates and standardizes the work required to maintain model performance over time.
A mature MLOps practice includes several core pillars:
- Continuous Monitoring: Track key metrics like latency, throughput, and cost per inference to identify performance issues before they affect users.
- Drift Detection: Models can become less accurate over time. Tools are needed to detect data drift (when input data characteristics change) and concept drift (when the real-world patterns being predicted change).
- Automated Retraining: Implement triggers that automatically initiate a retraining pipeline when a model's performance falls below a defined threshold. This keeps the system current without manual intervention.
Without this operational discipline, even a highly accurate model will degrade over time. MLOps transforms a static model into a system that can be maintained and improved.
Plan for Scalability and Governance
Scalability and governance are not afterthoughts. For any serious enterprise AI application, they are essential. Scalability should be integrated into the system's architecture from the start. Conduct load tests to identify system limits and design for sudden traffic increases, using tools like auto-scaling cloud groups or an effective edge deployment strategy.
Successful enterprise AI recognizes that the model is just one component. The true value comes from a well-managed, efficient, and reliable inferencing engine that consistently delivers business outcomes.
Alongside scalability, strict governance ensures AI systems operate safely and responsibly. Practices like model versioning, clear access controls, and detailed logging create an audit trail for compliance and debugging. As AI regulations become more common, a system to manage and document model behavior is critical. For teams preparing for standards like the EU AI Act, familiarity with tools for AI governance and quality assurance is a crucial step toward building trustworthy AI.
Common Questions on AI Inferencing
Here are answers to a few common questions about AI inferencing.
What's the Real Difference Between Inference and Prediction?
The terms inference and prediction are often used interchangeably, but there is a useful distinction. Inference is the process—the computation the data undergoes as it passes through the model's layers to arrive at a conclusion. The prediction is the result—the final output.
Using a GPS navigation analogy, the constant calculation of your position and the route is the inference. The final "You have arrived" message is the prediction. Inference is the "how," and prediction is the "what."
Is a GPU Really Necessary for AI Inferencing?
No. While GPUs are standard for the computationally intensive task of model training, inference can often run on a variety of hardware.
Many models perform adequately on standard CPUs, particularly for applications where a few milliseconds of additional latency are acceptable.
Furthermore, a large portion of the AI landscape, including smartphones and industrial sensors, cannot use power-hungry GPUs. These edge devices use specialized, low-power chips (like NPUs) designed for efficient inference without significant battery drain.
How Do You Actually Calculate the Cost of Inferencing?
Calculating the cost of inference involves determining the total cost to obtain a single prediction, which varies based on the deployment environment.
You must consider the complete picture:
- In the Cloud: The cost is typically based on the virtual machine resources (CPU or GPU time, memory) used to serve the model, often billed by the second or hour.
- On-Premises or at the Edge: This involves calculating the Total Cost of Ownership (TCO). This includes the upfront hardware cost plus ongoing expenses for electricity, cooling, and maintenance.
To simplify this, businesses often use a single metric: cost per million inferences. This helps track efficiency and ensure the AI feature provides a return on investment.
At DSG.AI, we bridge the gap between AI concepts and production systems that drive real business outcomes. Our architecture-first approach ensures your AI solutions are built to be scalable, dependable, and perfectly aligned with your operational reality. See how we've helped leading organizations turn their data into a true competitive edge by exploring our past projects.


