
Written by:
Editorial Team
Editorial Team
Ground truthing is the process of comparing data collected by a system, like an AI model or satellite, to direct, real-world observations. It creates a verified "answer key" used to train and test AI models. This process confirms that digital information accurately reflects physical reality.
This verification is a foundational step for building any AI system that requires reliable performance.
What Is Ground Truthing
To understand ground truthing, consider a navigation app. The app's map is the model's prediction of the world. The ground truth is what you see with your own eyes: the actual street signs, unexpected construction, and new one-way streets.
If the app directs you down a road that is now closed, its model is inaccurate. The act of observing this difference and knowing the real state of the street is ground truthing. It is the fundamental check of digital information against objective facts.

This process creates a highly accurate dataset, often called a "source of truth," for an AI to learn from. For any organization building AI, this is the foundation of reliability. Without it, the system learns from unverified assumptions, which can lead to poor performance and operational errors.
Why It Is the Bedrock of AI
A core principle of AI is that a model's accuracy cannot exceed the accuracy of its training data. A flawed answer key results in a flawed system. This applies whether the AI is designed to identify defects in manufacturing or predict customer churn from support tickets.
The process involves several core activities:
- Data Collection: Gathering raw information, such as images, sensor readings, or text.
- Human Annotation: Experts label the raw data with correct, verifiable answers. This is a critical step.
- Model Training: The AI learns by comparing its predictions to the ground truth labels.
- Performance Validation: The model's accuracy is tested against a new ground-truthed dataset it has not seen before.
In essence, ground truthing is the human-led effort that turns raw data into structured training material. It creates a high-fidelity representation of reality that a machine can use, forming the basis for any functional AI application.
To clarify, let's review the key components of ground truthing.
Ground Truthing Core Concepts at a Glance
| Component | Description | Business Implication |
|---|---|---|
| Source of Truth | A dataset verified against direct, real-world observations. | This is the gold standard for model training, validation, and establishing trust in AI-driven outcomes. |
| Data Labeling/Annotation | The process where humans assign context or outcomes to raw data (e.g., tagging images, categorizing text). | The quality of annotation directly impacts model performance. Poor labeling leads to unreliable results. |
| Verification & Validation | Cross-checking the ground truth data against the model's predictions to measure metrics like accuracy, precision, and recall. | This is how you objectively measure ROI, identify model weaknesses, and prove the system's reliability. |
| Iterative Refinement | The ongoing cycle of collecting new data, establishing ground truth, and retraining the model to improve performance. | AI systems require maintenance. This continuous process ensures the model adapts to changing conditions and avoids performance drift. |
Understanding these pillars is the first step toward building reliable, production-grade systems that deliver measurable business outcomes.
The Scientific Roots of AI Data Verification
The concept of "ground truthing" existed long before artificial intelligence. It is a scientific method used for decades in fields that connect digital data to the real world, such as cartography, remote sensing, and meteorology.

Consider the problem faced by early geographers. A satellite image might show a green area, but is it a forest, a farmer's field, or a marsh? The only way to know for certain was to send a person to the location to observe it directly. That act of on-the-ground verification is the core of ground truthing.
From Map Making to Machine Learning
This process of physical validation became a standard for data quality. In the early 1970s, as satellite technology advanced, NASA formally documented the need for ground truthing. Researchers traveled to specific locations to gather direct, empirical evidence.
They compared this "ground-level" data to information from satellites to calibrate and correct the remote readings. This work was essential for creating accurate digital maps and environmental classification systems. The same logic now drives supervised machine learning. An AI model is a complex map of a problem, and ground truth data provides the real-world landmarks it needs to learn the terrain.
This principle is used in many fields:
- Meteorology: Weather models are constantly checked against real-time data from physical weather stations.
- Cartography: Surveyors visit sites to confirm that topography on an aerial map matches reality.
- Ecology: Biologists physically count animal populations to validate migration patterns detected by radar.
This historical context shows that ground truthing is a fundamental quality control process built on scientific rigor. It applies the same discipline that makes a map trustworthy.
The Unchanging Principle of Verification
Even as AI models become more sophisticated, the need for this verification remains. Building a reliable AI system is similar to the scientific method: you form a hypothesis (the model's prediction) and test it against real-world evidence (the ground truth).
This connection clarifies the AI validation landscape. To understand how AI outputs are validated, learning how AI detectors identify machine-generated content provides an example of these principles.
Like a scientist verifying satellite imagery, these tools rely on ground-truthed datasets to learn the difference between authentic and synthetic media. The core concept is universal: comparing a new output against a known, verified source. This legacy of real-world validation is what makes modern AI credible for business decisions.
How Ground Truth Fuels Today's Machine Learning
In machine learning, "ground truth" is a verified answer key used to teach an AI how to understand and make decisions. Without this benchmark, an AI model operates without a way to confirm if its predictions are correct.
This is the foundation of supervised learning, a common approach for building AI. We show the model data that has been meticulously labeled by human experts.
For a synthetic example, imagine training an AI to detect tumors in medical scans. The process starts with thousands of raw X-ray images. A team of radiologists then reviews each image, drawing boxes around tumors and labeling them. This annotated dataset is the ground truth. The AI model trains by comparing its predictions against these expert labels, adjusting its logic until its analysis mirrors the radiologists' expertise.
The same process applies to other tasks, from identifying spam emails to powering self-driving cars. It turns raw information into a teaching tool.
From Piles of Data to Pinpoint Accuracy
The quality of your ground truth data sets a limit on your model's potential. An AI will never be more accurate than the data it was trained on. This makes the data labeling phase a critical part of the AI development process.
Here’s how this works in different fields:
- Customer Support AI: A team listens to thousands of recorded support calls and tags each one with a sentiment, like "Frustrated," "Satisfied," or "Neutral." This ground truth data trains a model to automatically triage incoming calls. Some systems can flag at-risk customers with over 90% accuracy based on internal company benchmarks from Q3 2023.
- Autonomous Vehicles: Human annotators spend thousands of hours reviewing driving footage, labeling every object—pedestrians, stop signs, cyclists, lane markers. This detailed ground truth teaches a self-driving car to perceive its environment and navigate safely.
In each case, human expertise is captured to create a machine-readable version of reality.
A machine learning model is like an apprentice. The ground truth is the master's instruction. If the master's examples are flawed, the apprentice will learn the wrong lessons.
The Unbreakable Chain: Data Quality to Model Performance
The direct link between ground truth quality and model performance is why companies invest in data annotation and quality control. Errors, biases, or inconsistencies in training data will be learned and often magnified by the AI.
If a sentiment analysis model is trained on mislabeled customer chats, it will consistently misread customer emotions, leading to poor service.
Likewise, an AI designed to find defects on a manufacturing line will fail if the initial examples of "defective" and "perfect" products were labeled inconsistently. The result is more than a poorly performing model; it's wasted materials, faulty products, and a loss of confidence in the system.
Creating high-quality ground truth separates a proof-of-concept AI from a reliable, production-ready system. It is the foundational investment that makes accuracy possible.
Achieving High-Quality Ground Truth Data at Scale
Defining ground truth is one part of the challenge. Producing it consistently across millions of data points is an operational one.
High-quality ground truth data is the result of a structured approach to quality assurance, review, and continuous improvement. This process treats data as a critical asset and transforms raw information into a reliable "source of truth" for training AI models.
The diagram below shows this flow. It illustrates how raw data becomes fuel for a trained AI model, with the labeling stage acting as a critical filter.
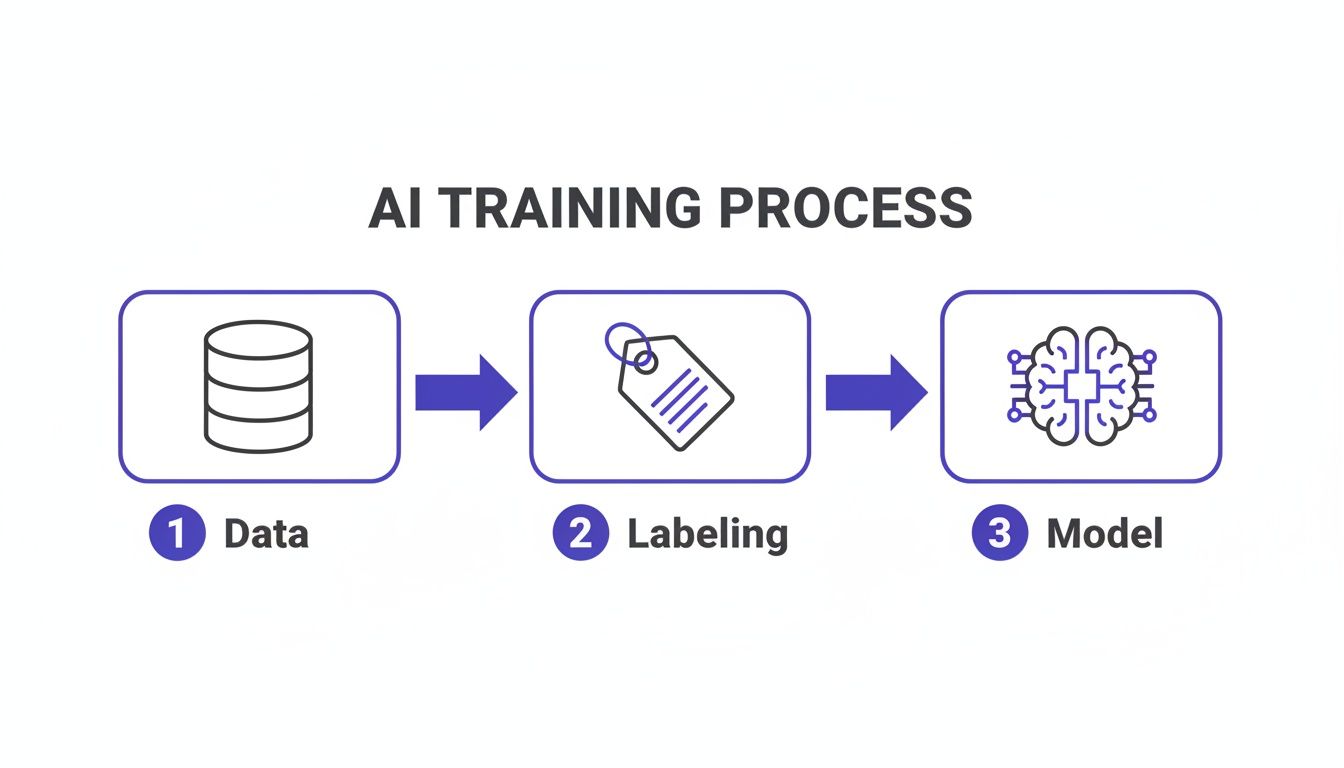
The quality of the labeling step determines the quality of everything that follows.
Building a Robust Quality Assurance Framework
A single person is rarely the sole arbiter of truth. Human judgment, even from experts, can be subjective.
To operationalize the definition of ground truthing, you need systems to measure and manage that subjectivity. A standard practice is to have multiple, independent annotators label the same piece of data. From there, you can calculate the inter-annotator agreement (IAA), a statistical score that measures labeling consistency.
A high IAA score, typically 90% or higher for production-grade systems, indicates clear labeling guidelines. A low score is a red flag signaling ambiguity that must be fixed before scaling up. For more information, a practical guide on How to Improve Data Quality can be a useful resource.
The goal is consistency, not just accuracy. A reliable ground truth dataset is one where multiple experts, working independently, consistently arrive at the same conclusion. This consensus makes the data trustworthy enough for a machine to learn from.
Designing Effective Review and Sampling Workflows
A multi-layered review process helps catch errors. Many teams use a tiered system where a subset of labeled data is passed to a senior reviewer for verification. If they find discrepancies, the items are flagged and sent back for correction. This creates a feedback loop that improves annotator performance over time.
Reviewing every label is often not feasible. Strategic data sampling makes this process more efficient.
- Random Sampling: Select a percentage of all labeled data (e.g., 5-10%) for a quality check.
- Targeted Sampling: Focus review efforts on difficult data, such as known edge cases, ambiguous examples, or data from a new source.
- Model-Assisted Sampling: Use an early version of your model to flag predictions where its confidence is low, then prioritize human review for those items.
These workflows are designed to make quality control both effective and efficient. By combining multi-annotator consensus, structured review cycles, and intelligent sampling, you can build a scalable process that produces consistently high-quality ground truth.
Ground Truthing Applications That Drive Business Value
High-quality ground truth data drives business results. The work of checking data against reality can lead to improved efficiency, less waste, and financial returns. When an AI model learns from an accurate picture of the world, it can perform its job with a precision that impacts the bottom line.

The link between data quality and business value is clear when looking at specific examples where the definition of ground truthing becomes practice.
Driving Efficiency in Agriculture
Precision agriculture provides a clear case. A company might use satellite imagery to forecast crop yields and check plant health over thousands of acres. Initially, these images are just pixels and require context.
To provide context, agronomists go into the fields to inspect sample plots. They check soil moisture, plant height, and signs of disease. This on-the-ground verification creates the ground truth data. That data is then used to train an AI model to read satellite imagery with higher accuracy. The resulting system can guide irrigation and fertilizer application with greater precision.
A well-grounded agricultural AI can lead to an 8 to 15 percent reduction in fertilizer waste, based on USDA precision agriculture studies. For a large farm, this represents a significant cost saving and an improvement in environmental sustainability.
Optimizing Retail Operations
In retail, keeping shelves stocked and organized correctly is an ongoing challenge. Brands pay for product placement, but ensuring every store follows the planogram is difficult.
Retailers now use AI to solve this. Employees take photos of store shelves, and a computer vision model analyzes them to spot out-of-stock items or misplaced products. The model’s accuracy depends on its ground truth training data, which consists of thousands of images where human annotators have marked every product.
- Initial Data: Raw photos of store shelves.
- Ground Truth: Each photo is labeled, identifying the exact location and name of every product.
- Business Outcome: The trained AI automatically flags shelves that do not match the plan. This allows for quick fixes and can reduce stockouts by up to 20% according to industry case studies. This recovers lost sales and improves the customer experience.
Ground truthing is a cornerstone practice in many sectors. Its impact is clear in agriculture, forestry, and remote sensing, where data accuracy directly affects operations. For more on this, gisgeography.com offers insights into how different industries apply this practice. Handling these complex data pipelines is a challenge; you can learn more about streamlining these workflows with AI orchestration.
Building the Business Case for Data Quality Investment
For technology leaders, new initiatives often come down to cost. With AI, the real question is the cost of not investing in data quality. Ground truthing is a risk mitigation strategy and a competitive advantage.
Failing to build a solid foundation of ground truth data creates costs later on. Some are quantifiable, like engineering hours spent fixing a failing model. Others are more severe, such as brand damage from a biased AI system. An inaccurate model is a direct threat to operations and customer trust.
From Technical Task to Strategic Asset
Viewing data quality as a strategic priority is becoming standard. The global data annotation market—which creates ground truth data—is projected to grow from $2.11 billion to $12.45 billion by 2033, according to market research reports. This signals that market leaders see data quality as a non-negotiable part of their AI budget. You can find more insights on this trend on articsledge.com.
This growth points to a shift in thinking. The definition of ground truthing has evolved from a niche task for data scientists into a core component of enterprise AI governance. The business case is straightforward: either invest proactively in creating a reliable source of truth, or pay more later to correct problems caused by bad data.
Investing in a high-quality ground truth dataset is one of the most effective ways to de-risk an AI project. It supports future success and transforms an experimental model into a reliable, production-grade business asset.
Justifying the Investment to Stakeholders
When presenting to executives, frame the discussion around asset creation and risk reduction. A well-built ground truth dataset is a durable corporate asset. It is not a one-time expense; it can be used to train, validate, and retrain models for years. The initial investment pays dividends by speeding up future projects and ensuring your AI systems are both accurate and auditable.
Maintaining the integrity of this process is essential. Integrated platforms that handle both quality control and governance are critical. For organizations that need to implement solid verification workflows, our assureIQ platform provides the tools to maintain data quality at scale. A well-funded data quality program is what separates a trusted, compliant AI system that delivers business value from one that creates problems.
Ground Truthing FAQs: Your Questions Answered
Practical questions often arise when implementing ground truthing. Here are answers to common questions about cost, workflow, and tools.
How Much Should We Budget for Ground Truth Data?
The cost depends on data volume, labeling complexity, and the level of expertise required.
A simple image classification task might cost a few cents per image. A synthetic example: asking a team of radiologists to segment tumors in MRI scans could involve specialist rates of hundreds of dollars per hour.
Frame this as an investment in model performance. A general guideline is to budget between 10% to 25% of total AI project development costs for data annotation, particularly when first building data pipelines.
Can We Just Automate the Whole Ground Truthing Process?
You can automate parts of the process, but you cannot remove human oversight entirely. The initial ground truth dataset almost always requires significant human intelligence.
Once you have an initial high-quality set, you can become more efficient. Techniques like active learning allow you to train a preliminary model, which then flags examples it is most uncertain about. Human experts can then focus their attention on those specific cases.
This "human-in-the-loop" strategy helps scale labeling efforts without a linear increase in cost. It does not fully replace the need for human oversight. You will always need an expert to verify quality, handle new edge cases, and ensure the model does not drift.
What’s the Difference Between Ground Truth and Training Data?
These terms are related but distinct. "Training data" is the raw material fed to the model. "Ground truth" is the verified answer key that tells the model what to learn.
Consider an email sorting model as an example:
- Training Data: The full text of thousands of customer emails.
- Ground Truth: The correct, verified category for each email (e.g., ‘Urgent Inquiry,’ ‘Spam,’ or ‘Invoice’).
You cannot have high-quality training data without first establishing an accurate ground truth. The labels are what give the raw data its meaning for the AI.
At DSG.AI, we help enterprises design, build, and operationalize AI systems that deliver measurable business value. Our architecture-first approach ensures your AI solutions are scalable, reliable, and built on a foundation of high-quality data. Learn how we turn data into a competitive advantage.


