Written by:
Editorial Team
Editorial Team
A loss function is a formula that measures how wrong a machine learning model's prediction is compared to the actual outcome. This measurement, called "loss," is a penalty score. The goal of training a model is to minimize this penalty.
This function provides feedback to the AI. It is how the model learns from its mistakes.
What Are Loss Functions and Why They Matter for Business AI
Imagine you're training an employee to price products. When they suggest a price, you tell them how far off they were—by $5 or $50. That feedback is the "loss." The loss function in AI does the same thing. It acts as a guide during the training process. Every time the model makes a prediction, the loss function calculates a score that shows how far it missed the mark.
This score is the engine for improvement. An optimization algorithm, like gradient descent, uses this loss score to tweak the model's internal settings. This process repeats thousands or millions of times. The model gradually learns to make predictions with the smallest possible error.
This concept map breaks down that feedback loop—comparing predictions to targets to generate a score that guides the model's learning.
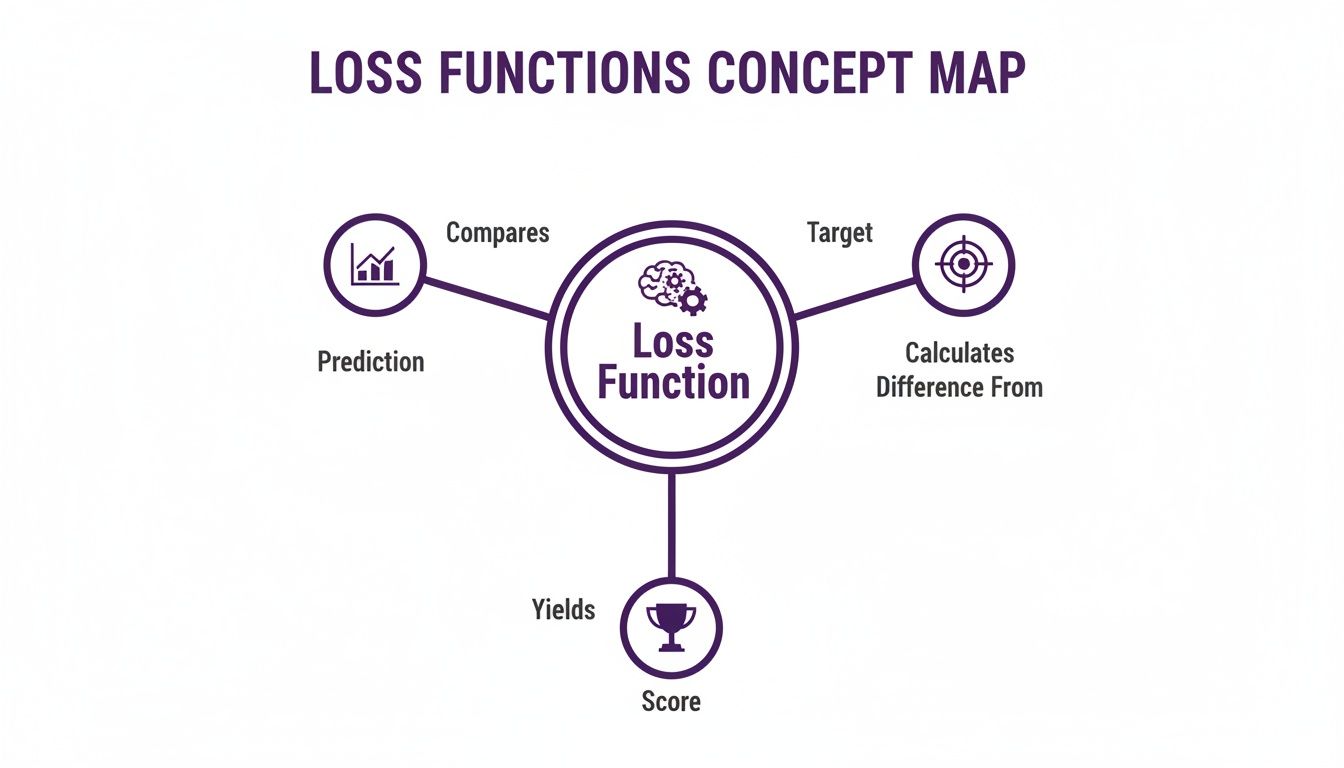
The loss function connects a model's output directly to its performance goal.
Connecting Technical Choices to Business Outcomes
Choosing the right loss function is a strategic business decision, not just a technical detail. The function you select dictates the model's behavior. It determines what kinds of mistakes the model will work hardest to avoid. For instance, in a fraud detection model, you might penalize a missed fraudulent transaction (a false negative) far more than incorrectly flagging a legitimate one (a false positive).
A loss function is the link between an AI model and business goals. It translates a business objective—like minimizing supply chain disruptions—into a mathematical objective that the model can optimize.
This alignment helps AI deliver measurable value. The concept dates to the 1950s with pioneers like John von Neumann and Frank Rosenblatt. They shifted focus from rigid programming to systems that could learn from data. By 1958, Rosenblatt's Perceptron used a basic loss-like mechanism to adjust itself based on errors. Early tests showed it achieved up to 90% accuracy on simple tasks.
There is no single "best" loss function. The right choice is tied to the specific business problem. Selecting it requires a strategic approach, a core part of effective enterprise AI management. A correct choice directly impacts operational efficiency, risk mitigation, and profitability.
Let's review the main categories of loss functions and their business applications.
Quick Overview of Common Loss Function Categories
This table maps different types of loss functions to the problems they are designed to solve.
| Loss Category | Primary Use Case | Example Business Problem |
|---|---|---|
| Regression | Predicting a continuous numerical value. | Forecasting product demand or estimating real estate prices. |
| Classification | Assigning an item to a specific category. | Identifying spam emails or classifying customer support tickets. |
| Ranking | Ordering a set of items by relevance. | Powering search engine results or product recommendation systems. |
| Robust Losses | Handling datasets with outliers or noise. | Predicting financial metrics in volatile markets. |
Each category contains multiple specific loss functions, each with its own mathematical properties and trade-offs. We will now cover these in more detail.
Picking the Right Loss Function for Regression Problems
When a machine learning model predicts a continuous number—like forecasting sales figures or estimating property values—it is a regression problem. The loss functions for regression measure the gap between the model's prediction and the actual number. Choosing the right one depends on how your business needs to treat mistakes.

Some prediction errors have minor consequences. Others can cause serious financial impact. Your choice of loss function teaches the model what to prioritize, aligning its training with your business goals. Let’s review the three most common loss functions for regression.
Mean Squared Error (MSE): The Strict Supervisor
The most common starting point for regression is Mean Squared Error (MSE), or L2 loss. It works by taking the difference between the predicted and actual value, squaring that difference, and then averaging all those squared errors.
The squaring operation is key. It punishes large mistakes exponentially. A prediction that's off by 4 units is penalized 16 times more than one off by 1 unit (since 4² = 16 and 1² = 1). This makes MSE a strict supervisor that strongly discourages large deviations.
When to use MSE: Use MSE when large errors are disproportionately damaging. It pushes the model to be careful and pay close attention to outliers, as they generate a large penalty that the model will work hard to avoid.
Business Example: A hedge fund uses an AI to predict stock prices for automated trading. A single, large prediction error could trigger a significant financial loss. Using MSE forces the model to minimize these high-stakes mistakes, prioritizing stability and precision.
MSE is a cornerstone for production AI systems where accuracy is critical. At DSG.AI, MSE was used in maritime fuel optimization and agricultural forecasting projects. Its implementation contributed to an 18% reduction in fuel consumption and a 22% increase in yield accuracy, based on performance data from Q3 2022 to Q2 2023. You can learn more about how loss functions are used in real-world machine learning.
Mean Absolute Error (MAE): The Forgiving Mentor
In contrast to MSE, Mean Absolute Error (MAE), or L1 loss, is more forgiving. It calculates the absolute difference between predicted and actual values and then averages them. There is no squaring, so each error is weighted in direct proportion to its size. A mistake of 4 units is penalized exactly twice as much as a mistake of 2 units.
This linear penalty makes MAE less sensitive to outliers. A single incorrect data point will not dominate the loss score and distort the model's predictions. This makes it a robust choice when a dataset is "noisy" or contains anomalies that the model should not overreact to.
Business Example: A manufacturing plant uses sensors to predict when equipment needs maintenance. Occasionally, a sensor might malfunction and send an extreme reading. Using MAE ensures these rare events do not disrupt the entire predictive model, leading to more stable maintenance schedules.
Huber Loss: The Pragmatic Hybrid
Huber Loss provides a middle ground between MSE’s strictness and MAE’s resilience. It is a hybrid that acts like two functions in one.
Huber Loss uses a defined threshold, called delta (δ).
- For small errors below the threshold, it acts like MSE, using a squared penalty to help the model fine-tune predictions with precision.
- For large errors above the threshold, it switches to act like MAE, applying a linear penalty to reduce the influence of outliers.
This dual behavior makes it a practical choice. It provides the smooth training of MSE for common errors and the robustness of MAE for outliers. To see if your AI initiatives could benefit from such an approach, consider an AI readiness assessment.
Business Example: A retail company forecasts demand for a new fashion line. Most days, predictions are close, and they want the model to be as precise as possible (favoring MSE). But occasionally, an item goes viral on social media, causing a large, unpredictable demand spike. Huber Loss allows the model to learn from typical patterns with high precision while not overreacting to these rare, outlier events.
Selecting a Loss Function for Classification Tasks
While regression models predict numbers, classification models assign labels. They answer questions like, "Is this a fraudulent transaction?" The goal is to pick the right category from a set of options.
The loss functions for classification work differently than in regression. Instead of measuring a numerical distance, they gauge how well the model's predicted probabilities match the actual class label. The right choice is crucial for building models that are accurate and appropriately confident.
Cross-Entropy Loss: The Industry Standard
The primary loss function for classification is Cross-Entropy Loss, also called Log Loss. It measures how much the model's predicted probability distribution differs from the true label (where the correct class is 1 and all others are 0).
Cross-entropy heavily penalizes confident but wrong predictions. If a model is 99% certain an email is safe but it is spam, the loss value is very high. If the model was only 51% sure and was wrong, the penalty is much smaller. This behavior forces the model to produce well-calibrated probabilities, not just guess labels.
Cross-entropy has been central to major machine learning advances. Its stability was a key factor in the success of deep learning models like ResNet-50. In 2015, ResNet-50 achieved a 3.57% top-1 error rate on the ImageNet dataset, an 87% relative improvement over older benchmarks. At DSG.AI, it is the core of logistics email classification systems that have reached 92% F1-scores. You can learn more about the impact of different loss functions in real-world ML applications.
This function comes in two main versions.
Binary vs. Categorical Cross-Entropy
Choosing the right version of cross-entropy depends on your classification problem.
- Binary Cross-Entropy: This is used for two-class (binary) problems. The model outputs a single probability (e.g., the chance of a customer churning), and the loss function is applied to it.
- Categorical Cross-Entropy: This is for multi-class problems (three or more categories). The model outputs a probability for each class, and the loss function compares this probability distribution to the true label.
Here are some practical examples:
| Business Problem | Number of Classes | Appropriate Loss Function |
|---|---|---|
| Customer Churn Prediction | 2 (Churn / No Churn) | Binary Cross-Entropy |
| Spam Email Filtering | 2 (Spam / Not Spam) | Binary Cross-Entropy |
| Product Categorization on E-commerce Site | 100+ (e.g., Electronics, Books) | Categorical Cross-Entropy |
| Medical Image Diagnosis | 4 (e.g., Normal, Benign, Malignant) | Categorical Cross-Entropy |
Matching the loss function to the problem ensures correct alignment of the model's output and loss calculation.
Hinge Loss: An Alternative for Maximizing Margins
While cross-entropy is common, Hinge Loss, associated with Support Vector Machines (SVMs), offers another approach. Instead of focusing on probabilistic accuracy, Hinge Loss aims to maximize the margin or separation between classes.
Hinge Loss does not penalize a prediction that is correct and far from the decision boundary. The loss is zero in this case. It only penalizes points that are misclassified or too close to the boundary.
This makes it effective for problems where a clean separation between categories is the top priority.
- When to Consider Hinge Loss: It is a strong choice for "maximum-margin" classification tasks where a robust decision boundary is more important than calibrated probabilities.
- Business Example: Consider a system that sorts documents into "Urgent" and "Non-Urgent." The main priority is to never misclassify an urgent document. Hinge loss would push the model to create a wide decision boundary, ensuring that questionable documents are flagged correctly.
While Cross-Entropy is the default for most classification tasks, alternatives like Hinge Loss provide a richer toolkit for specific business challenges.
Comparison of Regression and Classification Losses
This table highlights the core differences between key loss functions for regression and classification.
| Loss Function | Type | Mathematical Formula (Simplified) | Sensitivity to Outliers | Best For |
|---|---|---|---|---|
| Mean Squared Error (MSE) | Regression | (Actual - Predicted)² | High | General-purpose regression where outliers need to be penalized heavily. |
| Mean Absolute Error (MAE) | Regression | ` | Actual - Predicted | ` |
| Huber Loss | Regression | Hybrid of MSE and MAE | Medium | A balanced approach, acting like MSE for small errors and MAE for large ones. |
| Binary Cross-Entropy | Classification | -(y log(p) + (1-y) log(1-p)) | High (for confident errors) | Two-class classification problems where calibrated probabilities are important. |
| Categorical Cross-Entropy | Classification | -Σ(y log(p)) | High (for confident errors) | Multi-class classification problems. |
| Hinge Loss | Classification | max(0, 1 - y * f(x)) | Medium | Maximum-margin classification, especially with SVMs, where a clear boundary is the goal. |
The choice is not arbitrary. Each function tells the model what "good" looks like, shaping its behavior and performance.
Using Advanced and Custom Loss Functions to Solve Complex Problems
Standard loss functions work well for many common regression and classification tasks. But some business challenges are too specific for an off-the-shelf solution.
Advanced and custom loss functions allow a model to learn subtle relationships or prioritize certain outcomes.

These are practical tools for high-value business problems where standard methods may fail. They let you shape the model’s learning process to fit your data and business goals.
Advanced Loss Functions for Specialized Tasks
Standard loss functions often fall short with tricky data, like images or imbalanced datasets. Advanced options were developed to handle these scenarios more effectively.
-
Triplet Loss for Similarity Learning: Consider a recommendation engine. The goal is not just to classify items but to understand which ones are "similar." Triplet Loss is designed for this. It looks at three examples: an anchor (reference item), a positive (similar item), and a negative (dissimilar one). The loss function pulls the anchor and positive closer together in the model's representation while pushing the negative item further away. It teaches a model a sense of similarity.
-
Focal Loss for Class Imbalance: Now, think of a fraud detection system. Fraudulent transactions might make up less than 0.1% of the data. With standard cross-entropy, the model could achieve high accuracy by always predicting "not fraud." Focal Loss modifies cross-entropy to address this. It reduces the penalty for examples the model already gets right, forcing it to focus on the difficult, rare cases—the actual fraud instances.
These are just a couple of examples. A solid grasp of specialized loss functions is essential for optimizing advanced AI, like the models used in unlocking value with Large Language Model applications.
Designing Custom Loss Functions for Business KPIs
You can design a loss function that directly reflects a unique business key performance indicator (KPI). This aligns the model's mathematical objective with a tangible financial or operational outcome. Instead of optimizing for a generic metric like "accuracy," you optimize for what the business values.
A custom loss function translates your specific business costs and priorities into a mathematical objective that the model can directly minimize. This is the ultimate alignment of AI with business value.
The process involves identifying the asymmetric costs of different mistakes and writing that logic into a formula.
Synthetic Example: An Inventory Management Model Let's design a custom loss for a model that predicts weekly product demand. The business knows the costs:
- Cost of Under-stocking (Lost Sales): $50 per unit.
- Cost of Over-stocking (Storage & Waste): $10 per unit.
A standard Mean Squared Error (MSE) loss would treat predicting 10 units too few and 10 units too many as equally bad. But for the business, under-stocking is five times more costly.
A custom loss function can capture this. We can build a function that applies a penalty multiplier of 5 for under-predictions and a multiplier of 1 for over-predictions. By training the model on this custom loss, you minimize real-world business cost, not just error.
From Theory to Trenches: Putting Loss Functions to Work
Choosing a loss function has real consequences once a model is deployed. A good choice can make training smooth. The wrong one can create operational problems. This is where a deep understanding of loss functions in machine learning is valuable.
A loss function shapes the training process. A function with a smooth surface, like MSE, usually offers a straightforward path to optimization. A function with sharp angles, like MAE, can make the process more erratic. The optimizer might require a lower learning rate to maintain stability.
Reading the Tea Leaves: What Your Loss Curve is Telling You
The loss curve is a valuable tool. Plotting the loss value over each training epoch shows what is happening during training.
- A steady decline? This indicates the model is consistently learning.
- Hitting a plateau? The loss flatlining might mean the model has learned all it can, or the learning rate is too low.
- Jumping all over the place? A volatile curve is a sign of instability, often caused by a learning rate that is too high.
- Training and validation curves diverging? When training loss drops while validation loss rises, this indicates overfitting. The model is memorizing the training data, not learning general patterns.
Monitoring these curves helps spot trouble early, saving time and compute resources.
Loss Functions and the Push for Responsible AI
A loss function's impact extends beyond technical performance to responsible AI. A standard loss function optimizes for overall accuracy. It is unaware of fairness or biases in the training data.
If your training data reflects historical biases—for example, a bank that historically approved fewer loans for a certain demographic—a standard loss function will learn and often amplify that pattern.
This is a significant risk. A model trained with a naive loss function can make systematically unfair decisions in hiring, credit scoring, or medical diagnostics. This poses legal and reputational risks, especially with new regulations like the EU AI Act. Building fair AI requires fairness-aware loss functions or other specialized techniques.
Beyond the Loss Score: Monitoring in the Wild
Once a model is live, its original loss score is not enough. Data distributions shift and customer behavior changes. A model's performance can degrade in ways the loss function does not capture. Solid MLOps practices, like continuous monitoring against business metrics, are critical. You can learn more from MLOps best practices for production AI.
For example, a churn prediction model could maintain a low cross-entropy loss. But if the marketing cost to acquire a new customer doubles, the model's business value has decreased, even if the technical metric is stable. You must track the KPIs the business cares about, such as customer lifetime value or campaign ROI.
Specialized monitoring and governance tools are essential. They ensure models are accurate, fair, compliant, and driving business value. Platforms that integrate Responsible AI and governance, like DSG.AI's assureIQ, bridge this gap. They provide continuous oversight for managing AI systems in production.
Turning Technical Decisions into Business Value
A loss function is the bridge connecting a model's training process to your business objectives. We have covered the basics through real-world applications.
We started with core loss functions for regression and classification. The choice between Mean Squared Error and Mean Absolute Error reflects business priorities for handling different types of mistakes. We then covered advanced and custom functions for complex problems like class imbalance or optimizing for a specific financial KPI.
From Formula to Function
Choosing among loss functions in machine learning is a strategic act. This decision should be a primary consideration, driven by the specific problem, data characteristics, and desired outcomes.
Building enterprise-grade AI requires deliberate, architecture-first thinking. Choosing the right loss function is an example of translating technical choices into measurable, reliable, and responsible business value.
This single choice affects model behavior, training stability, and fairness. A carefully selected loss function teaches the model to avoid the most expensive errors, whether measured in dollars, operational issues, or reputational damage.
Your Next Step in Enterprise AI
Getting this right is the difference between building models and engineering solutions. It ensures every component, including the loss function, is chosen to advance a specific business goal. This mindset separates AI systems that are merely clever from those that are indispensable assets.
The next step is to apply these principles to your own data and workflows. To see how this strategic approach can solve your biggest challenges, look at some real-world AI projects and case studies.
Common Questions About Loss Functions
Here are answers to common questions about loss functions.
How Is a Loss Function Different From a Performance Metric?
This is a key distinction. A loss function is for the machine, and a performance metric is for humans.
The loss function guides the model during training. It must be differentiable, a mathematical property that allows the training algorithm to know how to adjust the model's parameters.
A performance metric is used to judge the final model. It connects the model's output to a business outcome. Metrics like accuracy, F1-score, or customer lifetime value are chosen because they are easy for stakeholders to interpret. While some functions like MSE can serve as both, many key business metrics are not differentiable and cannot be used directly for training.
A loss function is the model's teacher during training, providing continuous, differentiable feedback. A performance metric is the final exam, grading the model on how well it solves the business problem.
Can I Use Multiple Loss Functions for One Model?
Yes, this is a powerful technique used in multi-task learning, where a single model handles several responsibilities.
For example, a self-driving car's perception model must identify objects (classification) and pinpoint their location (regression). This requires a combined loss function. You might blend a classification loss (like Categorical Cross-Entropy) for identification with a regression loss (like MSE) for location. You can assign weights to each part of the loss to prioritize tasks.
When Should I Create a Custom Loss Function?
Consider a custom loss function when the business cost of different errors is not symmetrical. If your problem has unique penalties or rewards, a standard loss function may be inadequate.
Consider a retail inventory forecast:
- Cost of Under-prediction (Stockout): Lost profit of $50 per item.
- Cost of Over-prediction (Excess Stock): Storage cost of $10 per unsold item.
A standard MSE loss treats both mistakes as equally bad. In reality, a stockout is five times more costly. By designing a custom loss function that heavily penalizes under-predictions, you optimize the model to avoid the most expensive business mistake.
At DSG.AI, we specialize in designing and building enterprise-grade AI systems where every component, including the loss function, is architected to solve specific business challenges. Explore our real-world AI projects and case studies to see how we turn technical decisions into measurable business impact.


